What is HDFS (Hadoop Distributed File System)?
HDFS stands for Hadoop Distributed File System. It is the file system of the Hadoop framework. It was designed to store and manage huge volumes of data in an efficient manner. HDFS has been developed based on the paper published by Google about its file system, known as the Google File System (GFS).

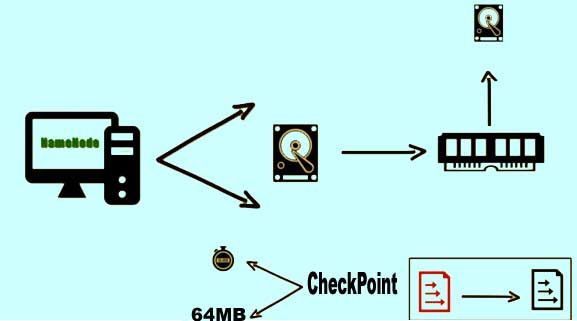
HDFS is a Userspace File System. Traditionally file systems are embedded in the operating system kernel and runs as an operating system process. But HDFS is not embedded in the operating system kernel. It runs as a User process within the process space allocated for user processes, on the operating system process table. On a traditional process system the block size is of 4-8KB whereas in HDFS the default block size is of 64MB.
- HDFS <- GFS
- Userspace File System
- Default Block Size = 64 MB
Advantages of HDFS
- It can be implemented on commodity hardware.
- It is designed for large files of size up to GB/TB.
- It is suitable for streaming data access, that is, data is written once but read multiple times. For example, Log files where the data is written once but read multiple times.
- It performs automatic recovery of file system upon when a fault is detected.
Disadvantages of HDFS
.jpg)
- It is not suitable for files that are small in size.
- It is not suitable for reading data from a random position in a file. It is best suitable for reading data either from beginning or end of the file.
- It does not support writing of data into the files using multiple writers.
Hadoop Daemons Core Component
An understanding of the Hadoop distributed file system Daemons
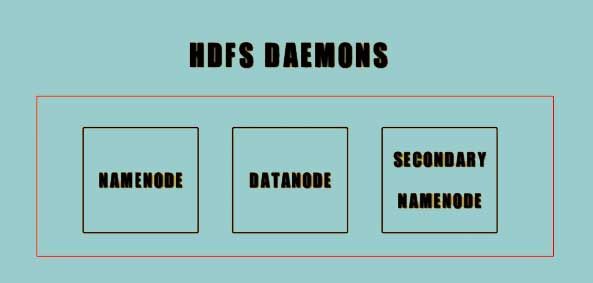
This HDFS consists of three Daemons which are:-
- Namenode
- Datanode
- Secondary Namenode.
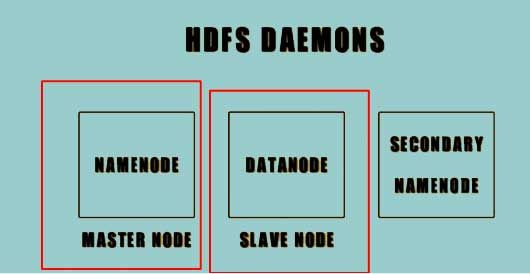
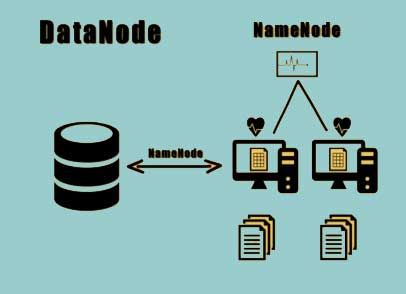
All the nodes work the primary slave architecture.
The Namenode is the master node while the data node is the slave node. Within the HDFS, there is only a single Namenode and multiple Datanodes.
Functionality of Nodes
The Namenode is used for storing the metadata of the HDFS. This metadata keeps track and stores information about all the files in the HDFS. All the information is stored in the RAM. Typically the Namenode occupies around 1 GB of space to store around 1 million files.
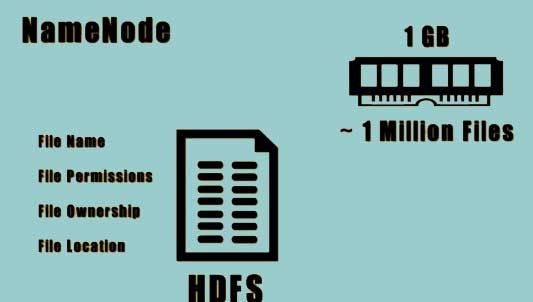
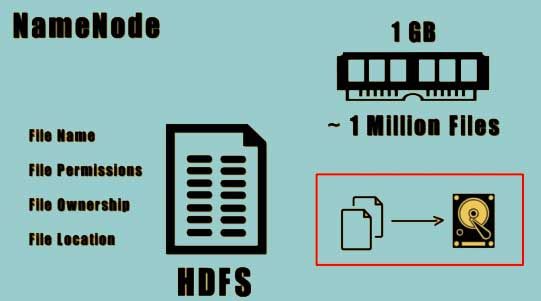
The information stored in the RAM is known as file system metadata. This metadata is stored in a file system on a disc.
The Datanodes are responsible for retrieving and storing information as instructed by the Namenode. They periodically report back to the Namenodes about their status and the files they are storing through a heartbeat. The Datanodes stores multiple copies for each file that is present within the Hadoop distributed file system.
Apart from storing the file system metadata in the RAM, the Namenode also stores this information on a set of files. The two important files among them are the fsImage file and the Edit Log file. The fsImage stores the complete snapshot of the file system metadata whereas the Edit Log file contains all the incremental modifications done to the metadata.
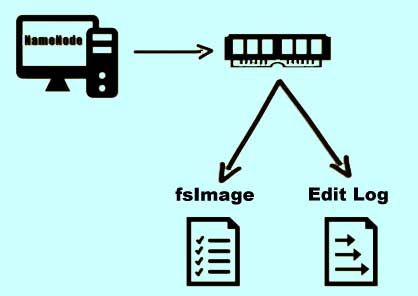
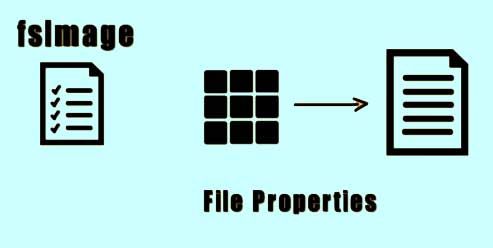
The fsImage file stores information about all the blocks that belong to a file and the file system properties.
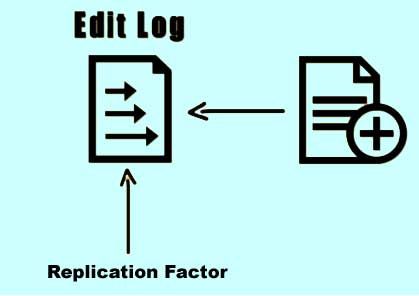
The Edit Log, on the other hand, keeps track of all the transactions that take place on the file system. For example when a new file is created and an entry is made into the Edit Log file. Another example - if the replication factor is changed then an entry is made in the Edit Log file.
How to manage File System Metadata in detail?
When the Namenode starts it reads their fsImage and Edit Log file from the disk and applies all the transactions to the metadata from the Edit Log file that has been copied to the RAM.
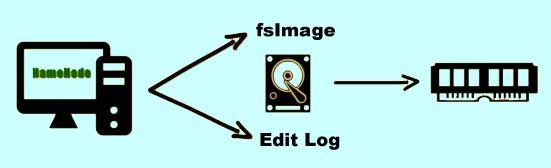
A new version of their fsImage is written on to the disk from the memory. In this new Edit Log file all the old entries are truncated. This process is known as a checkpoint and occurs every hour or whenever the Edit Log file reaches to 64 MB in size, whichever occurs first.