MySQL
MySQL is a Relational Database Management System (RDBMS) that functions on the basis of the Structured Query Language (SQL). The software is open-source under the GNU General Public License and is a fast and efficient software that is compatible with all operating systems including Windows, Linux and UNIX. The software that is backed by Oracle is the most popular relational database software due to its ease of use, proven reliability and flexibility.
Prerequisites to Learn MySQL
MySQL is a database management software for managing relational databases. So, it is imperative for anyone to be well acquainted with the concept of a database and the terminology associated with it before getting started with a RDBMS like MySQL. And since this particular RDBMS is based on SQL, it is also important for one to know the basics of the query language before venturing into learning MySQL.
Advantages of MySQL Database
MySQL is favoured by most businesses due to the array of advantages it has over its competitors.
Open Source and Easy to Use: The MySQL server is open source and is thus free for all to download. For the same reason, it is cost-efficient as well and since anyone can modify it, it is more up to date. The installation process of MySQL is easy and since third-party tools can be included in the database, it takes relatively lesser effort to set up an installation.
Data Security: WordPress, Facebook, Twitter, Drupal, Joomla and others favour the MySQL database because it is the most reliable and secure RDBMS. Any business that involves money transfers prefers MySQL because of the data security that all transactional processing entail.
On-Demand Scalability: On-demand scalability and flexibility are the star features of this RDBMS. The system offers scalability that facilitates managing embedded apps in huge warehouses storing terabytes of data.
Portability: MySQL is a platform-independent system. It is highly compatible with all platforms including Linux, Solaris, Windows and others. MySQL is the most suitable system for the web applications targeting multiple platforms.
High Performance: The system has a storage-engine framework and it helps the system administrators in configuring the database server. If it is a website that receives more than a million queries, MySQL is designed in a way to meet any demand at an optimum speed.
Tutorials
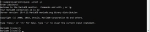 Error 1045 (28000) access denied for user root localhost
Error 1045 (28000) access denied for user root localhost
MySQL users often face an issue called Error 1045 (28000) access denied for user 'root'@'localhost' (using password: yes). This usually occurs when you enter an incorrect password or p ...- How to Fix the 'Error: MySQL Shutdown Unexpectedly' Problem in XAMPP?
Users working on the MySQL platform encounter an error called “Error: MySQL shutdown unexpectedly”. Issues in the database and corrupted files are some of the reasons behind this error. So ... - Can't connect to local mysql server through socket 'varrunmysqldmysqld.sock' (2)
Have you ever experienced this error "can't connect to local mysql server through socket '/var/run/mysqld/mysqld.sock' (2)?" Users can fix this error if they find the right probl ... - Import and Export Database in MySQL or MariaDB using SQL file
In software development, developers often need to import and export databases in MySQL and MariaDB to create a backup. It looks efficient and faster until users face using large databases of more than ...