Hadoop Introduction
Hadoop is an open source big data framework developed by Doug Cutting in the year 2006. It is managed by the Apache Software Foundation. The project was named after Hadoop, a yellow stuff toy which Cutting’s son had.

Hadoop is designed to store and process huge volumes of data efficiently.

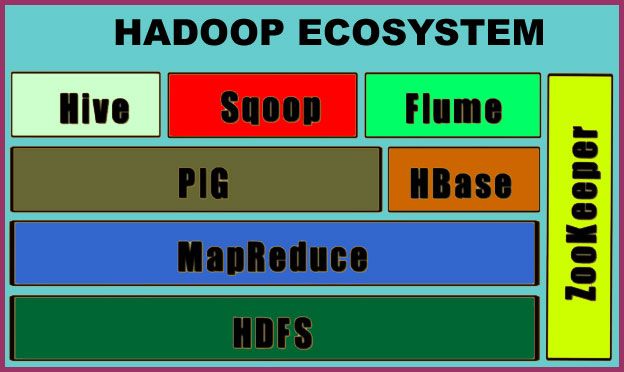
Hadoop framework comprises of two main components:
- HDFS - It stands for Hadoop Distributed File System. It takes care of storing and managing the data within the Hadoop cluster.
- MapReduce - It takes care of processing and managing the data present within the HDFS.
What makes up a Hadoop cluster?
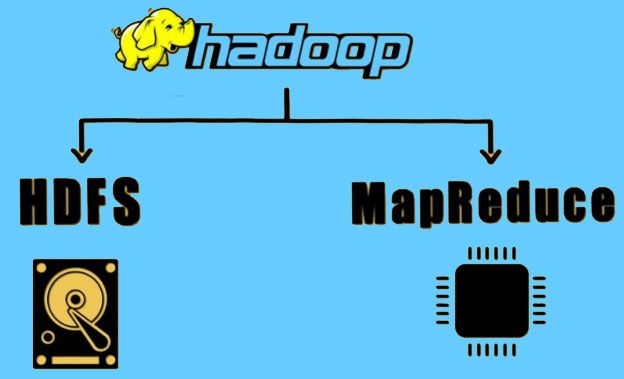
1) A Hadoop cluster is made up of two nodes. A node is a technical term described to denote a machine or a computer present within a cluster. The two nodes present in the Hadoop cluster are:
- Master Node- It is responsible for running the Name node and the Job Tracker Demons.
- Slave Node- It is responsible for running the Data node and the Task Tracker Demons.
2) Demon is a technical tern used to describe a background process that is running on a Linux machine.
3) Name node and Data node are responsible for storing and managing the data. They are commonly referred to as Storage Node
4) Job Tracker and Task Tracker are responsible for processing the data and are commonly referred to as Compute Node.
5) Generally, Name node and Job Tracker are configured on the same machine whereas Data node and Task Tracker are configured on multiple machines, but can have instances of running in more than one machine at the same time.
6) There is also a secondary name node as part of the Hadoop cluster.
Hadoop Ecosystem Architecture
The success of Hadoop network has led to the development of an array of software. All these software along with Hadoop make up the Hadoop ecosystem.

The main objective of this software is to enhance functionality and increase the efficiency of the Hadoop framework.
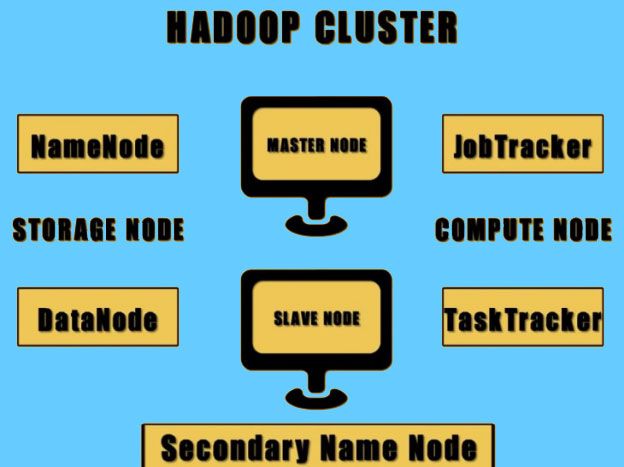
The Hadoop Ecosystem comprises of-
1) Apache PIG
It is a scripting language used to write data analysis programs for large data sets that are present on the Hadoop Cluster. It is also called as PIG Latin.
2) Apache HBase
It is a column oriented database that allows reading and writing of data onto the HDFS on a real time basis.
3) Apache Hive
It is a SQL like a language that allows squaring of data from HDFS. The SQL version of Hive is called Hive QL.
4) Apache Scoop
It is an application that is used to transfer data to and from Hadoop to any relational database management system.
5) Apache Flume
It is an application that allows moving streaming data into a cluster. For example, data that is being written into log files.
6) Apache ZooKeeper
It takes care of all the coordination required among all these software to function properly.