In Python, pandas is an open-source library that programmers use for working with data sets. Pandas DataFrame is a size-mutable, two-dimensional, tabular data structure having rows and columns.
To merge two DataFrames is one of the typical practices in Python using the pandas library. From this article, programmers can get a detailed knowledge of the various methods of merging DataFrames.
What is a Pandas DataFrame?
Users widely use this pandas DataFrame (data structure) to work with any two-dimensional array with tabular format data having axes, i.e., rows and columns. We can define a DataFrame as a standard way to store data having two separate indexes, i.e., row and column index. It includes the properties mentioned below:
- Users can use data types like int, bool, and other, which implies it is a heterogeneous data structure.
- Users can assume a DataFrame as a dictionary of Series structure having both the rows and columns indexed.
In Python, users can merge DataFrames that allow them to create a new DataFrame without changing the actual DataFrame's data sources or changing/modifying the original data source.
Some different functions and methods help programmers merge DataFrames.
These are as follows:
- merge() function
- join() method
- concat() function
- append() function
- update() method
Method 1: Using the merge() function to merge pandas DataFrames:
Let us start with our first method to merge DataFrames using the merge() function. When users use the merge() function, it creates a new DataFrame by merging them.
Syntax:
dataframe.merge(right, on, how, left_on, right_on, left_index, right_index, sort, suffixes, copy, indicator, validate)
Let us see the code snippet and understand how it works:
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name': ['A', 'B', 'C', 'D'],
'Address': ['Sipraganj', 'Noida', 'South City', 'Malda'],
'Age': [35, 31, 29, 40],}
# Define a dictionary containing employee data
data2 = {'Name': ['A', 'B', 'C', 'D'],
'Salary': ['50000', '49000', '45700', '51200'],
'Phone Number': ['0000000000', '1111111111', '2222222222', '3333333333']}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df = df1.merge(df2, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
print(df)
Output:
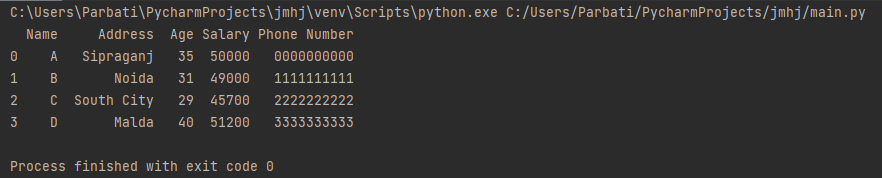
Explanation:
Here, in this code snippet, we have used the merge() function with two DataFrames. The syntax of this function is variable_name=first_dataframe.merge(second_dataframe, parameters). The function first merges the first dataframe with the second dataframe creating a new dataframe having all the data sets of both.
Note:
Users can use the merge() function in four primary ways. These are by handling the dataframes and joining left, right, inner, or outer, based on which rows must have their data.
Method 2: Using the join() method to merge pandas DataFrames:
The join() is a method of DataFrame, which users can use like a static method on the DataFrame. It helps to join the columns of another DataFrame either on a key column or index. When users call the join() method, it will be the left DataFrame, by default. While using other parameters, it will create a new right DataFrame.
Syntax:
dataframe.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
Code:
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name': ['A', 'B', 'C', 'D'],
'Address': ['Sipraganj', 'Noida', 'South City', 'Malda'],
'Age': [35, 31, 29, 40], }
# Define a dictionary containing employee data
data2 = {'Name': ['A', 'B', 'C', 'D'],
'Salary': ['50000', '49000', '45700', '51200']}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df = df1.join(df2, rsuffix='_right')
print(df)
Output:
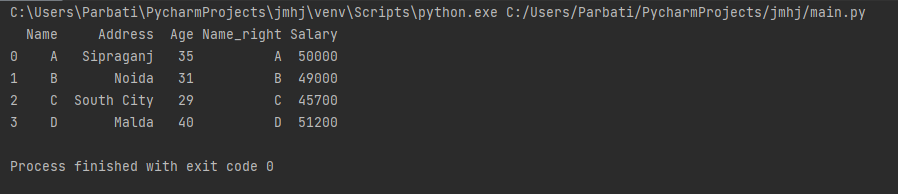
Explanation:
Here, we have joined the second DataFrame with the first DataFrame. It results in new data sets having columns of both the first and the second. Similar to the merge() function, the join() method automatically attempts to match the columns (keys) with the same name. In our case, it's the name key. Also, this method will not display the duplicate columns if users use that particular column key as an index on both columns. Thus, this will join without a suffix:
Code:
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name': ['A', 'B', 'C', 'D'],
'Address': ['Sipraganj', 'Noida', 'South City', 'Malda']}
# Define a dictionary containing employee data
data2 = {'Name': ['A', 'B', 'C', 'D'],
'Email ID': ['dhh36@demo.com', 'hgwiy2614@demo.com', 'abcd123@demo.com', 'xyz12345@demo.com']}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df_join_no_duplicates = df2.set_index('Name').join(df1.set_index('Name'))
print(df_join_no_duplicates)
Output:
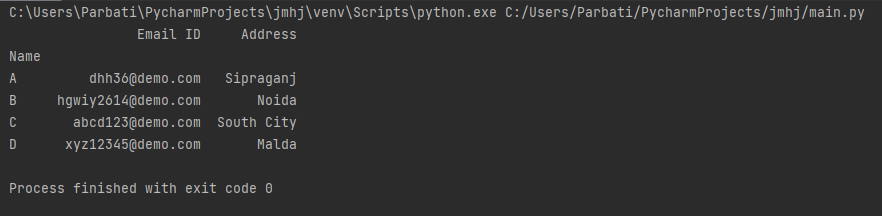
Method 3: Using the concat() function to merge pandas DataFrames:
Compared to the merge() and join() of DataFrame, the concat() function is more flexible and efficient. It allows users to join DataFrames either row-wise (vertically) or column-wise (horizontally). The concat() function combines two DataFrames by the indices of both DataFrames' values.
Syntax:
Syntax: concat(objs, axis, join, ignore_index, keys, levels, names, verify_integrity, sort, copy)
Code:
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name': ['A', 'B', 'C', 'D'],
'Age': [35, 31, 29, 40],
"Salary": ['46000', '56000', '48000', '40000'],
'Phone Number': ['9999999999', '6666666666', '4444444444', "8888888888"]}
# Define a dictionary containing employee data
data2 = {'Name': ['E', 'F', 'G', 'H'],
'Salary': ['50000', '49000', '45700', '51200'],
'Phone Number': ['0000000000', '1111111111', '2222222222', '3333333333']}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df = pd.concat([df1, df2])
print(df)
Output:
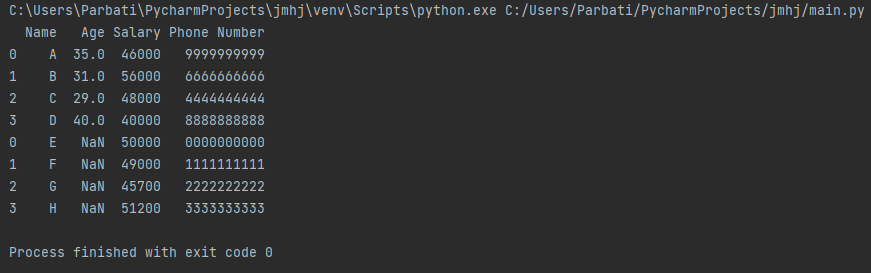
Explanation:
In the above code snippet, we have concatenated two DataFrames using the concat() function. The function concatenates the data sets either row-wise or column-wise.
Method 4: Using the append() function to merge pandas DataFrames:
The append() function is one of the useful functions to append data sets of two DataFrames in row axis only. Users can use the Pandas dataframe.append() function to append rows of another DataFrame to the end of the first DataFrame. It returns a new dataframe object.
Syntax:
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
Code:
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name': ['A', 'B', 'C', 'D'],
'Age': [35, 31, 29, 40],
"Salary": ['46000', '56000', '48000', '40000'],
'Phone Number': ['9999999999', '6666666666', '4444444444', "8888888888"]}
# Define a dictionary containing employee data
data2 = {'Name': ['E', 'F', 'G', 'H'],
'Salary': ['50000', '49000', '45700', '51200'],
'Phone Number': ['0000000000', '1111111111', '2222222222', '3333333333'],
'Age': [29, 26, 35, 38]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df = df1.append(df2, ignore_index=True)
print(df)
Output:
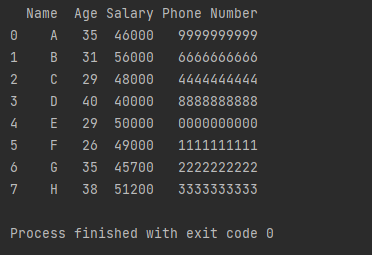
Explanation:
Here, we have used to append() function to combine the two data sets. But most users prefer concat() over the append() because it provides the axis option and key matching of the DataFrame objects.
Note:
The append() method is deprecated, and the Python community will remove it from pandas in the future version. So users are recommended to use the concat() function instead.
Method 5: Using the update() function to merge pandas DataFrames:
Users often want to fill the missing data in their DataFrame. They can do this by combining the original DataFrame with another DataFrame. Doing so will retain all the non-missing values in the first DataFrame and return all NaN values with non-missing values of the second DataFrame.
Syntax:
dataframe.update(other, join, overwrite, filter_func, errors)
Code:
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name': ['A', 'B', 'C', 'D'],
'Age': [35, 31, 29, 40],
"Salary": ['46000', '56000', '48000', '40000'],
'Phone Number': ['9999999999', '6666666666', '4444444444', "8888888888"]}
# Define a dictionary containing employee data
data2 = {'Name': ['E', 'F', 'G', 'H'],
'Salary': ['50000', '49000', '45700', '51200'],
'Phone Number': ['0000000000', '1111111111', '2222222222', '3333333333'],
'Age': [29, 26, 35, 38]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df1.update(df2)
print(df1)
Output:
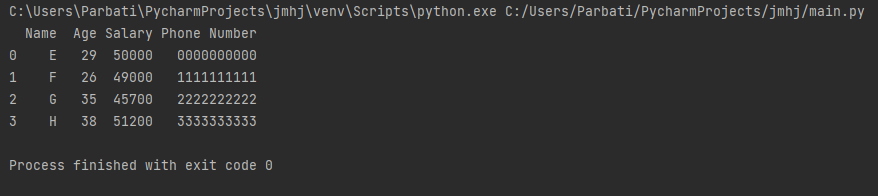
Explanation:
The update() method updates the data sets and creates a new DataFrame. The function replaces the data sets of the first DataFrame over the second by updating.
Conclusion:
The article has discussed all the methods of merging DataFrames using the pandas package in Python. But it can be difficult for programmers which technique to choose for merging DataFrames at the right time.
While principally, the merge() function is adequate. But for some cases, users may have to use concat() to concatenate row-wise. Among all these methods, the concat() method is straightforward while the append is the most common and efficient one.