Python supports file handling and allows users to access and manipulate files using the Python program. File handling became an essential part of different applications. The concept of file handling helps in storing a massive collection of data across various types of files. Python supports a wide range of functions to create, read, update, and delete files. In this article, you will learn about files and how different functions along with modes are used for handling files.
What are Files?
Files are named locations, usually reside in the secondary storage. Files allow users to store specific types of data or information. These data are stored permanently in the non-volatile memory. If you want to read data from a file or write data to a file, you have to open it first.
Types of Files:
Python allows programmers to create and use two different types of files. These are:
Text Files:
These are the most common type of file programmers use on a daily basis. Text files use Unicode or ASCII character encoding scheme to store characters. The default character encoding in text file depends on the operating system and the settings of your programming environment. Text files often terminate (deliminate) each line with a special character known as EOL (End of Line).
Internal translations are performed automatically depending on the Python and the operating system in which it is running. Text files are specific subset of binary files. We can store human readable characters in the form of rich text document or as plain text. Examples of text files:
- Tabular data: .csv, .tsv, etc.
- Documents: txt, .tex, .rtf, etc.
- Web standards: html, .xml, .css, .json etc.
- Configuration: ini, cfg, reg, etc.
Binary files:
These are typical files that store data in the form of bytes. It holds information in the same format as is held in the memory. These files, when called or opened return data to the interpreter (without any specific encoding or translation).
It does not even have a delimiter for the lines. It stores data in a cluster of bytes grouped in 8 bits or 16 bits format. These bits represent different formats of data. Binary files can store different types of data (database, text, spreadsheets, images, audio, etc.) under a single file.
Binary files are preferred because they are faster and easier to program. Also, these files are an excellent way of storing program or system information. But binary files are more likely to get corrupt if a single bit gets changed from the file. Examples of binary files
- Document files: .pdf, .doc, .xls etc.
- Executable files: .exe, .dll, .class etc.
- Image files: .png, .jpg, .gif, .bmp etc.
- Audio files: .mp3, .wav, .mka, .aac etc.
- Video files: .mp4, .3gp, .mkv, .avi etc.
- Database files: .mdb, .accde, .frm, .sqlite etc.
- Archive files: .zip, .rar, .iso, .7z etc.
Creating a File
If you want to create a file that can store plain text, then, you can use the .txt or .dat files. To create a file, we can simply go to Notepad and create a blank file and save it with a .txt or .dat file extension. Otherwise, we can use the write and append modes to create a file while opening it.
Opening a File
Opening a file helps in both reading and writing to it. Python's open () function helps in opening a file in reading or writing mode. This function will return a file object. This file object will be used to perform various other file handling operations in the Python code. The open() takes two arguments - first the file name that we want to create or open; the second is the mode in which the file will be opened. The mode argument is optional.
The syntax for opening a file using open() is:
open(file_name, file_opening_mode).
There are 3 basic modes of opening a file in Python. These are:
- r: for reading only; returns error if the named file doesn’t exist
- w: for writing to a file; creates the named file if it doesn’t exist
- a: for appending new data to the file; creates the named file if it doesn’t exist
Apart from that, we can use the two other modes
- r+: for both reading & writing
- x: for opening the file for exclusive creating a file; returns an error message if the named file exists prior to the creation
By default, a file opens in reading mode if we do not mention any argument in the second parameter.
Program:
# creating the file object
fobj = open('file_name.txt', 'r')
# Printing every line one by one from the file
for parsee in fobj:
print (parsee)
Output:
Working in read mode:
To read a file in Python, programmers should open it in the read mode. Three different methods allow us to fetch data from the file and display it in our Python output screen. To read a file using these methods, you have to create the file object first.
read():
It reads n bytes of data. If no byte size is specified, it will read the entire file. This method will return the read bytes in the form of strings.
The syntax is:
<filehandling object>.read(n)
Program:
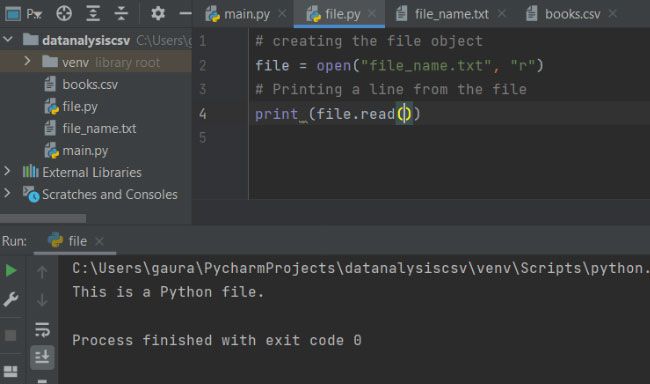
# without passing the argument in read()
file = open("file_name.txt", "r")
print ('File Output: ',file.read())
# by passing the argument in read()
# it will print number of character from begning of file
file = open("file_name.txt", "r")
print ('File Output with argument: ',file.read(12))
Output:
File Output: Apple
Banana
Orange
Mango
Grapes
Pomegranate
File Output with the argument: Apple
Banana
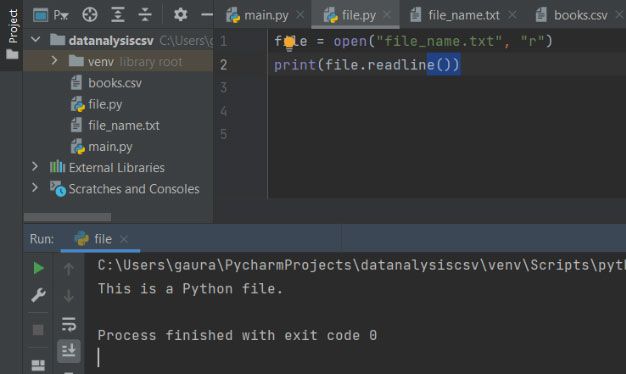
readline():
This method reads a line of input. If the argument is passed mentioning the n bytes, it will read at most n bytes. This method returns the bytes read from the file in the form of strings and ending with a ‘\n’ character. It will return a blank string when there isn’t any byte left in the file for reading. The argument ‘n’ is optional. The default value for the size (n) parameter in this method is -1.
The syntax is:
<filehandling object>.readline(n)
Program:
file = open("datafile.txt", "r")
file.readline()
readlines():
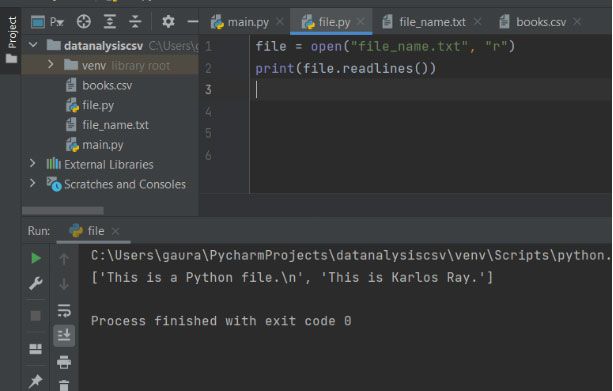
This is another file reading method that will read all the existing lines from the file and returns them as a list. The readlines() will accept one parameter i.e., n. The default value of this parameter is -1. The method will return all the lines. If the programmer explicitly mentions the value in the parameter. It will not display or read those lines that are exceeding this number (n) of bytes.
The syntax is:
<filehandling object>.readlines(n)
Program:
file = open("datafile.txt", "r")
file.readlines()
Working in write mode:
Once you are done reading the pre-existing file, it is time to write data to the file. There are two different methods available in Python to write data to the file stream. Also, you have to open the file in write or append mode (w or a). The various methods are:
write():
This method is used to set the specific string to the opened file from the user. It writes the byte of data to the referenced file. It writes the specific text depending on the file mode & the stream position. It takes a single parameter.
The syntax is:
<filehandling object>.write(string)
Program:
fobj = open("datafile.txt", "w")
fobj.write(" New Data added ")
fobj.close()
# opening & reading data from the file after appending data
fobj = open("datafile.txt", "r")
print(fobj.read())
ī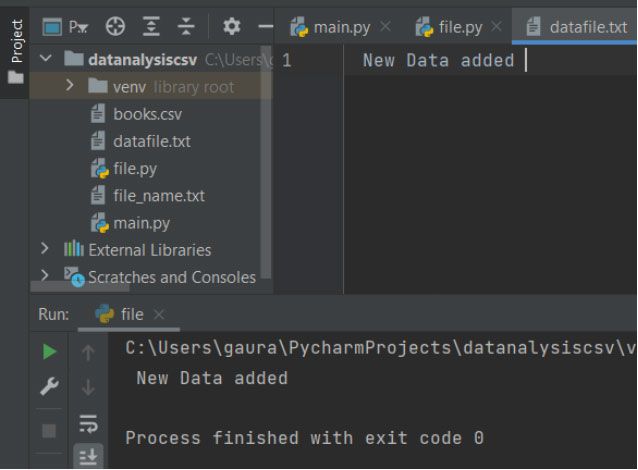
or,
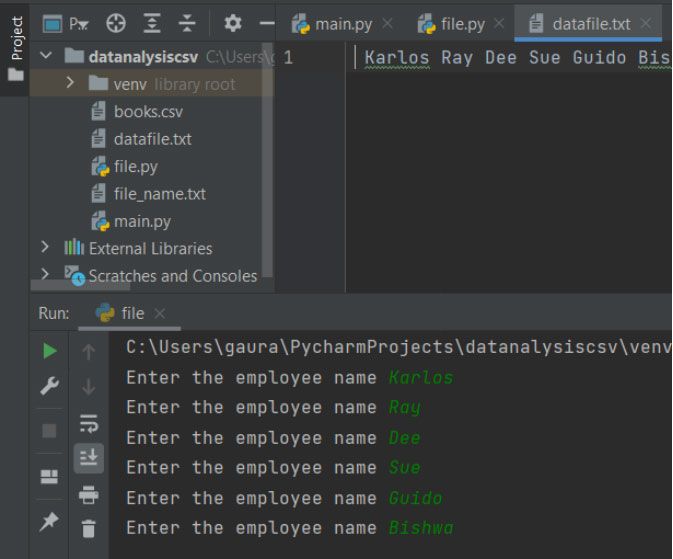
fobj = open("datafile.txt", "w")
for elem in range(6):
n = input("Enter the employee name")
fobj.write(n)
fobj.close()
Explanation:
Here, we have opened the datafile.txt in write mode with the file object name fobj. Then, we create a list of string with some name. Next we have used the write() that takes a string value to feed it into the file through the fobj file object. After closing the file, we are reopening it using the read mode. Then we are printing the data from the file using the fobj.read().
In the second case, we have opened the datafile.txt in write mode with the file object name fobj. We have used a range-based for loop that iterates 6 times for taking different iterable objects as parameter in the write(). The variable ‘n’ will take a name each time and write it to our file object.
writelines():
It will write a sequence of strings to the specified file. The sequence of string can be any iterable Python object such as a string or list of strings. It takes an iterable object as parameter and does not return any value.
The syntax is:
<filehandling object>.writelines(sequence / iterableObject)
Program:
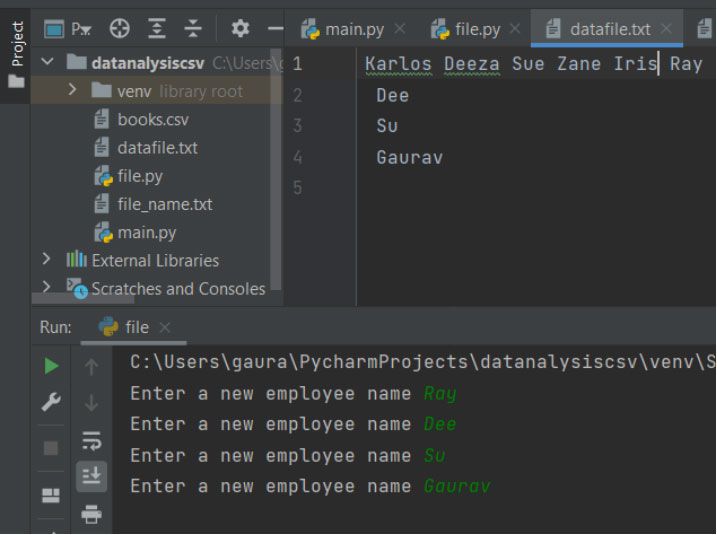
fobj = open("datafile.txt", "w")
li = ["Karlos", "Deeza", "Sue", "Zane", "Iris"]
for elem in range(4):
n = input("Enter a new employee name")
li.append(n + "\n")
fobj.writelines(li)
fobj.close()
Output:
Explanation:
Here, we have opened the datafile.txt in write mode with the file object name fobj. Then, we create a list of string with some name. In this program, we want four more values and for this reason, we have used a range-based for loop that iterates 4 times for taking different string inputs. Then, we are appending those values to the li object. The writelines() will write all the strings listed in the li object. Finally, we are closing the file using the close().
Working in Append mode:
Appending data to a file means opening the file for writing. If the file does not exist, the append ("a") will create a file with the specified name. Apart from "a", programmers can use the append and read ("a+") as file access mode. This mode is used for opening the file for reading as well as writing.
Program:
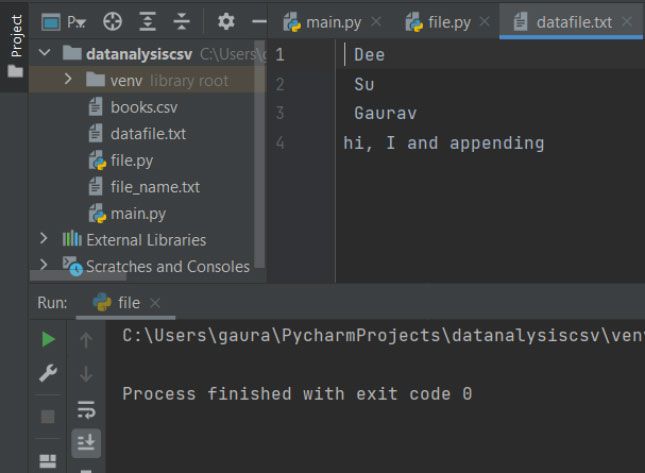
fobj = open('datafile.txt', 'a+')
fobj.write('hi, I and appending')
Absolute and Relative Paths:
We can define Path as a sequence of directory names or a combination of folder and sub folder names that allows us the way to access a particular file or data on our computer. It is of two types –
Absolute path:
An absolute path is a way or location that defines the file location or folder location regardless of the present working directory. While opening a file, if you use the absolute path, you explicitly mention the entire path starting from the root directory. It includes the complete file or folder location and is hence called absolute. Python allows using two different approaches to define the absolute path.
Example:
# using the path directly requires \\ escape sequence
fobj = open ("E:\\STechies 2021\\ Python\\filehandling.txt", "rw+")
# using the raw string format
fobj = open (r"E:\STechies 2021\Python\filehandling.txt", "rw+")
Relative path:
Relative paths directly target the location of the file relative to the current working directory. Therefore, the file and the python code should remain in the same directory to make the relative path working. It is preferred for developing website codes where the files are located on the same domain. In this case, if you change the Python program's location or path, you have to take that file also along with it.
Example:
fobj = open ("filehandling.txt", "rw+")
File pointers:
File pointers are an essential element of a file handling mechanism in any programming language. Because of file pointers, programmers can handle the position of the cursor in a file from within the program.
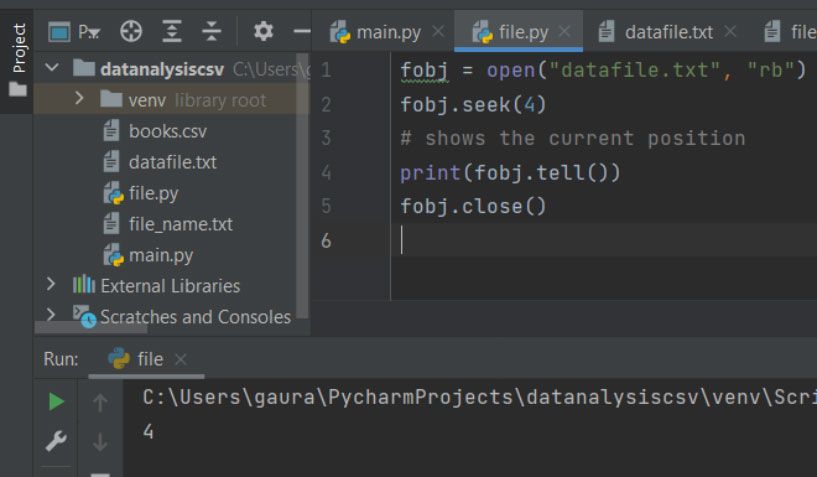
seek() and tell():
The seek() method helps in altering the position of the file handler to a particular location within a file. The Filehandle is like the cursor we use in MS. Word or notepad that determines where our next data will get inserted. It also defines where our data will be read or written to in the file. The seek() allocates the position of the file handler depending on the argument passed in it.
The syntax is:
fobj.seek(offset value, from_where)
- It accepts two arguments. First, the offset value determines the number of bytes to move.
- The from_where argument determines the position from where your specified bytes will move.
There are some reference points that programmers need to assign selecting using the from_where argument value.
0: is used for setting the reference point to the beginning of the current file
1: is used for setting the reference point at the current file position
2: is used for setting the reference point at the end of the current file
The tell() is used to return the file pointer's current position. It tells us about the position of the file handler or the cursor where the data will be feed. This method will take no parameters but will return an integer value.
The syntax is:
fobj.tell()
Program:
fobj = open("datafile.txt", "rb")
fobj.seek(-5, 10)
# shows the current position
print(fobj.tell())
fobj.close()
Output: