Comma Separated Values (CSV) is one of the most widely-known formats for sharing data in rows and columns within a program. Many data science professionals and enterprises use CSV files to store and fetch data for using them as the dataset. Python allows reading and writing all the data from the CSV file using some modules. In this article, you will learn about the different approaches we can use to read and write files with CSV.
What are CSV files?
CSV (Comma Separated Values) files are specific data storing formats that help in storing data in a tabular style. A CSV file's structure can be interpreted in a spreadsheet or database format. Developers can store data in plain text (usually, string & number data type), and each of these data is separated by a comma representing the data in rows and columns.
Each line of a .csv file defines a data record. The record contains one or more fields, and the values have a comma (also called the delimeter) identifying them discretely.
Reading and Writing CSV files using Pandas:
Pandas is one of the most common libraries for data analysis. It has different data structures: Series, DataFrames, and Panels. Among all these data structures, the DataFrame helps in structuring the column in a tabular format. Hence, it is the most commonly used data structure in creating and managing datasets or analysis in the field of data science.
This powerful module helps in data analysis and data manipulation very easily using some predefined modules. The CSV file is the most common file format to work with datasets.
Pandas use the DataFrame to display the ccsv file’s data. Developers can effortlessly and simply manipulate CSV files through the Pandas module. It has two built-in methods: read_csv() and to_csv() read and write to CSV files respectively.
Program:
import pandas as pd
data = {
'IND': {'COUNTRY': 'India', 'POP': 1_398.72, 'AREA': 9_596.96,
'GDP': 12_234.78, 'CONT': 'Asia'},
'CAND': {'COUNTRY': 'Canada', 'POP': 1_351.16, 'AREA': 3_287.26,
'GDP': 2_575.67, 'CONT': 'Asia', 'IND_DAY': '1947-08-15'},
'USA': {'COUNTRY': 'US', 'POP': 329.74, 'AREA': 9_833.52,
'GDP': 19_485.39, 'CONT': 'N.America',
'IND_DAY': '1776-07-04'},
'THAI': {'COUNTRY': 'Thailand', 'POP': 268.07, 'AREA': 1_910.93,
'GDP': 1_015.54, 'CONT': 'Asia', 'IND_DAY': '1945-08-17'},
'BRAZ': {'COUNTRY': 'Brazil', 'POP': 210.32, 'AREA': 8_515.77,
'GDP': 2_055.51, 'CONT': 'S.America', 'IND_DAY': '1822-09-07'},
'BDSH': {'COUNTRY': 'Bangladesh', 'POP': 205.71, 'AREA': 881.91,
'GDP': 302.14, 'CONT': 'Asia', 'IND_DAY': '1947-08-14'},
'NGA': {'COUNTRY': 'Nigeria', 'POP': 200.96, 'AREA': 923.77,
'GDP': 375.77, 'CONT': 'Africa', 'IND_DAY': '1960-10-01'},
'BHT': {'COUNTRY': 'BHUTAN', 'POP': 167.09, 'AREA': 147.57,
'GDP': 245.63, 'CONT': 'Asia', 'IND_DAY': '1971-03-26'},
'RUS': {'COUNTRY': 'Russia', 'POP': 146.79, 'AREA': 17_098.25,
'GDP': 1_530.75, 'IND_DAY': '1992-06-12'},
'GER': {'COUNTRY': 'GERMANY', 'POP': 126.58, 'AREA': 1_964.38,
'GDP': 1_158.23, 'CONT': 'N.America', 'IND_DAY': '1810-09-16'},
'JPN': {'COUNTRY': 'Japan', 'POP': 126.22, 'AREA': 377.97,
'GDP': 4_872.42, 'CONT': 'Asia'},
'UAE': {'COUNTRY': 'UAE', 'POP': 83.02, 'AREA': 357.11,
'GDP': 3_693.20, 'CONT': 'Europe'},
'FRA': {'COUNTRY': 'France', 'POP': 67.02, 'AREA': 640.68,
'GDP': 2_582.49, 'CONT': 'Europe', 'IND_DAY': '1789-07-14'},
}
columns = ('COUNTRY', 'POP', 'AREA', 'GDP', 'CONT', 'IND_DAY')
df = pd.DataFrame(data = data, index = columns)
print(df)
df.to_csv('Country_data.csv')
Output:
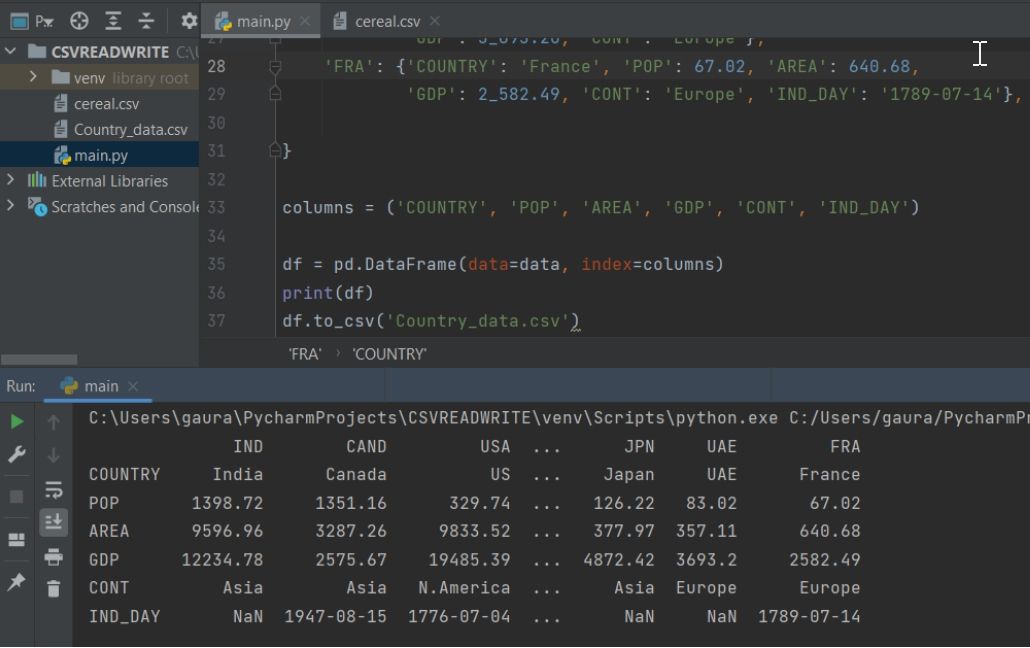
Explanation:
First, we have imported the pandas and aliasing it as pd. Then, we have used the concept of nested dictionary (named it as data) to create a Pandas DataFrame. We have also created a separate string-containing tuple that will specify the column names that will be displayed in the DataFrame.
Then we have used the pd.DataFrame() to create the dataframe from that data dictionary. We then print it using the print() function and finally used the df.to_csv() to take these data to CSV file.
Program:
import pandas as pd
dataf = pd.read_csv("Country_data.csv")
print(dataf)
Output:
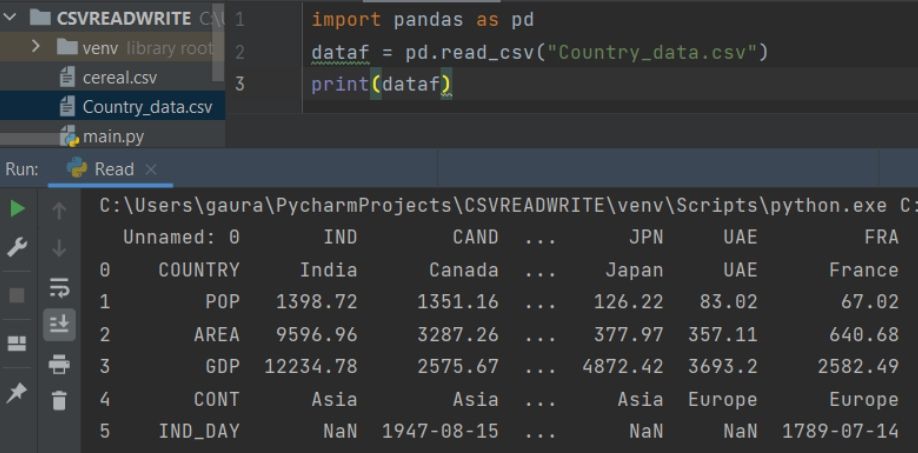
Explanation:
First, we have imported the pandas and aliasing it as pd. Then, we have used the read_csv() method of the pandas to read the CSV file. It acceps the absolute or relative csv file path as its parameter. We then store that file data in the dataf object and use the print() function to print the value of CSV files.
Reading and Writing CSV files using Python’s CSV module:
When programmers want a set of data that you would store in a CSV format, they can also use the writer() function of the CSV module instead of Pandas. For iterating the data over the rows(lines), you have to use the writerow() function.
Program:
import csv
with open('ProgrammingLang.csv', mode='w') as f:
writer = csv.writer(f, delimiter = ',', quotechar = '"', quoting = csv.QUOTE_MINIMAL)
writer.writerow(['LAGUAGES', 'CREATORS', 'CAME IN', 'FILE EXT'])
writer.writerow(['Python', 'Guido van Rossum', '1991', '.py'])
writer.writerow(['C++', 'Bjarne Stroustrup', '1985', '.cpp'])
writer.writerow(['Java', 'James Gosling', '1995', '.java'])
Output:
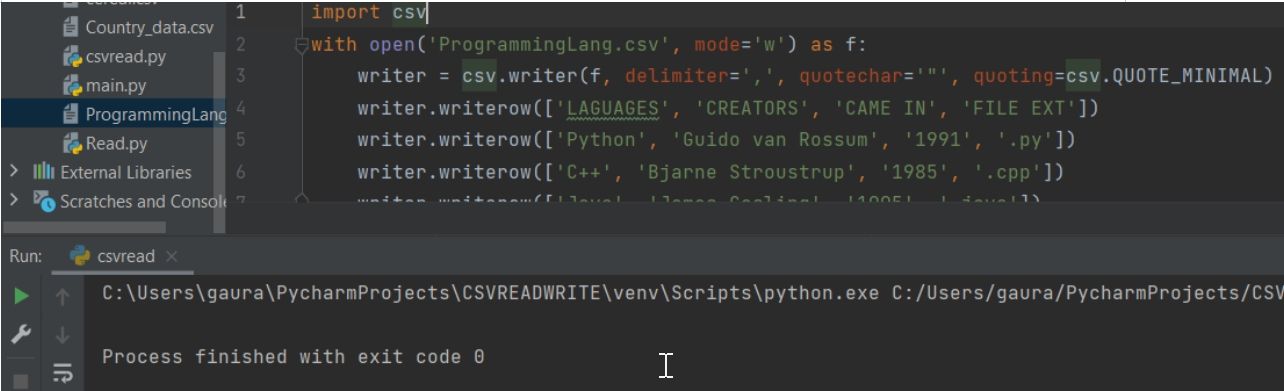
Explanation:
Here we have to import the csv module first. Then we will use the with open to open the csv file where we want to store our data as comma separated values. While opening the file, we will also specify the mode of the file (here write mode).
Then, we will use the csv.writer() to specify the format and way we want to store the data. To repeat the adding of data over the rows (lines), we have used the writerow().
Program:
import csv
r = csv.DictReader(open("ProgrammingLang.csv"))
for dat in r:
print(dat)
Output:
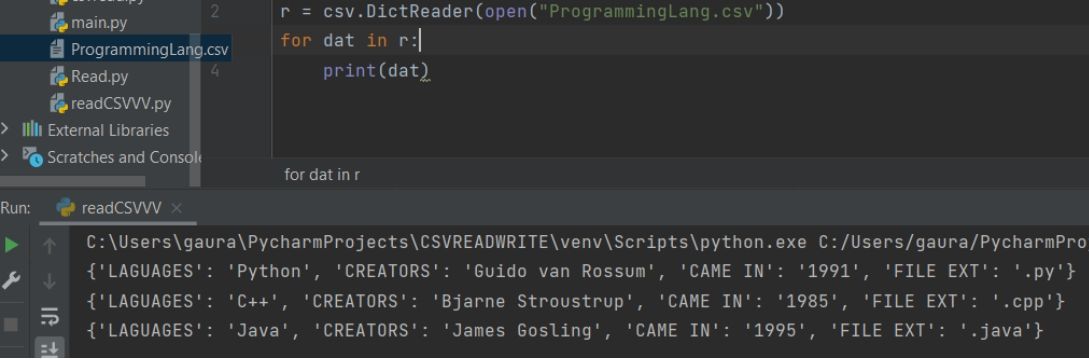
Explanation:
First, we will import the csv module. Then we will use the DictReader() method and pass the absolute or relative path of the csv file as its parameter. We then assign the entire value in an object (here r). Then we have to run a for loop till r that will read each row line by line and will fetch from the csv to display it as dictionary. Lastly, within that for we have to use the print().
Conclusion:
Among these two modules, Pandas is commonly used in data science related operations. But Pandas is less efficient as compared to CSV. CSV is a pre-existing module that Python programmers do not have to install separately. But Pandas needs installing. Data in CSV are mostly basic Python data types like dictionary.
But in Pandas, the data structure it uses to display or store csv is in DataFrame. If you are not planning for any Data Science related operations, then you can go with the CSV module.