Writing data to Hadoop HDFS
Let us understand the process with an example :-
1) For example, to write a file named ‘data.txt’ within the /user/Hadoop folder.
data.txt ----> /user/hadoop
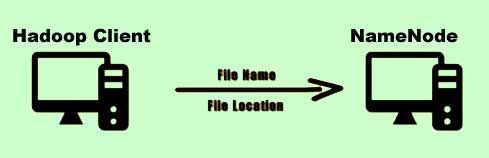
2) The client would send a request to the Namenode along with the filename and the file location to be created.
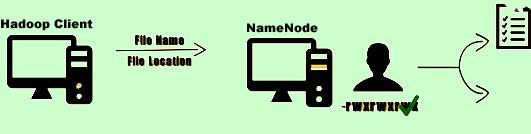
3) If the requested user has the appropriate permissions, an entry is made within the metadata list of the Namenode.
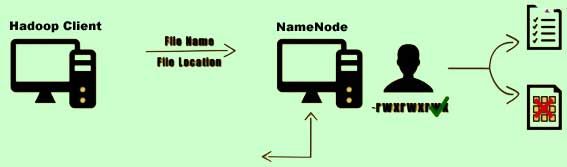
4) Initially, no blocks are associated with this file. Now the Namenode opens a stream to which the client can write data.
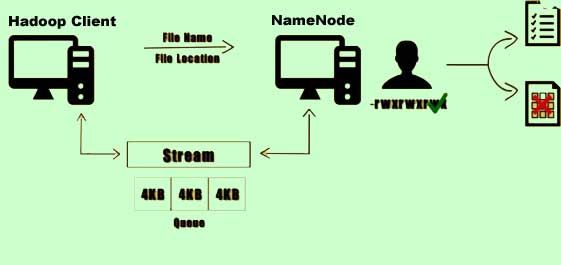
5) Now the Namenode opens a stream to which the client can write data. As the client writes data to the stream, the data is split into packets of 4 kilobytes and stored on a separate queue in the memory.
6) Now at the client’s end a separate thread is responsible for writing data from the queue onto the HDFS.
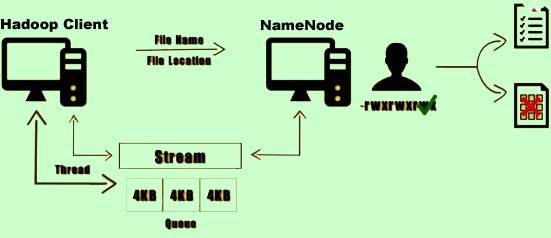
7) This thread would contact the Namenode requesting the list of all the Datanodes on which it can store the copy of this file.
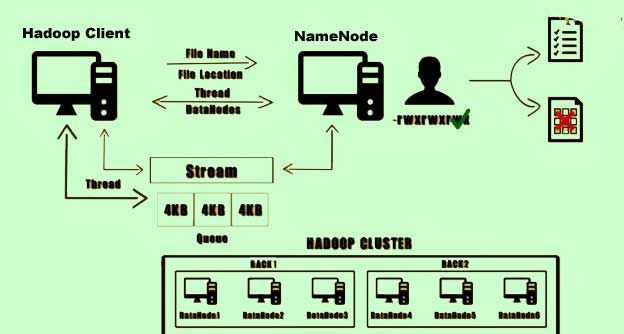
8) Now the client makes a direct connection to the first Datanode. the data has written to the first Datanode. Once this is completed the second Datanode in the list is replicated with the same data.
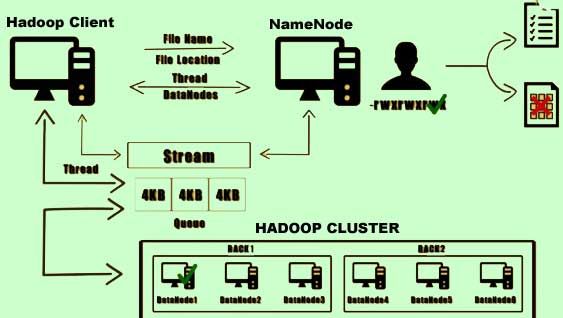
9) Once this is completed the second Datanode in the list is replicated with the same data, usually within the same rack and the process is repeated for the third data node in the list which is usually located on a different rack belonging to the same cluster.
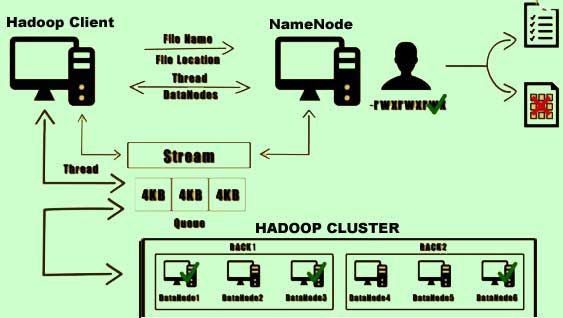
10) Once the packet a successfully returned to the disk, an acknowledgement is sent to the client. Upon reaching the block size the client would get back to the Namenode requesting next set of data notes on which it can write data. The client indicates the completion of writing the data by closing the stream. Any remaining packets in the queue are flushed out and meta data information is updated on the Namenode.
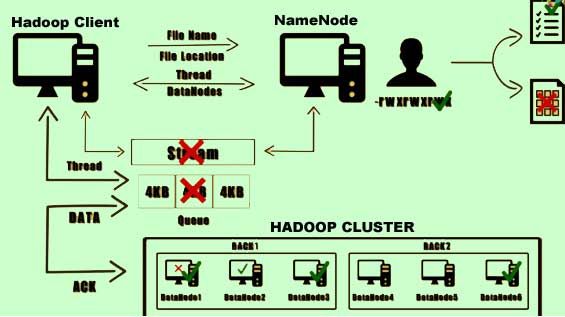
11) Errors can occur during the right process for various reasons. For instance if the disk of the Datanode on which the data was being written fails then the pipeline is immediately closed. Any data sent after the last acknowledgement is pushed back to the queue. A healthy data node is identified and a new block ID is assigned. And the data is transferred.