There are 3 Major Areas for ABAP Performance Tuning
- Select statements
- Internal table usage
- Database index
Select Statements
- Ensure that data is selected with primary key /secondary index support with the fields in the select statement’s WHERE clause in the same order as fields in the index
- Avoid negative WHERE clause (“NE”) because negative where clauses disable the index
- Avoid long selects within AT SELECTION-SCREEN event
Related: LOOP AT with WHERE Clause
Select Statements Where Clause Fields
- Select up to 1 rows when 'where' clause fields <> 'primary key fields‘
E.G. Select MATNR UPTO 1 rows from VBAP Where VBELN = ‘0001500080’ - Select single when 'where' clause fields = 'primary key fields'
E.G. Select single AUDAT VBTYP from VBAK Where VBELN = ‘0001500080’
Joined Select Statements
- Select with join instead of nested select statements, if the number of records to be fetched is more than 5. Ensure that the join fields are the keyed fields
- Limit tables in a join to three tables
Select Statements Contd..
- Select fields only instead of select *, when no. Of fields < 1/3rd of total fields in table or no. Of fields getting selected less than or equal to 16.
- Use SAP standards views for multiple table data selection
- Data should not be selected within loop .. Endloop statements. Instead use the select statement in join or for for all entries
- Select with where condition instead of checking them yourself with check-statements in transparent tables, else use the check statement in the pooled/cluster tables.
- For a buffered table, if a program does require the latest data from a table it is better to qualify the SELECT statement with ‘BYPASSING BUFFER’ specification
- Accesses to cluster type tables via non-key selection criteria should be avoided if possible
- Select using an aggregate function (SUM, MIN, MAX, COUNT) instead of computing the aggregates yourself
- Use select into table than select + append statement
Internal Table Usage
- Check whether the internal table has records in it before executing the validation checks and related processing steps for that internal table.
Example – before ‘for all entries in itab1’, ‘loop at itab1’ - It is more efficient to use the AT statements ( AT NEW, AT END OF, AT LAST ...) for summing and control breaks purpose. Avoid using ON CHANGE OF
- If using loop at WHERE statement never use internal tables events such as AT new inside the loop…Endloop
- All internal table reads with binary search only, after sorting it on the 'with key' fields
- To add data to an internal table and keep it sorted, use a READ with… BINARY SEARCH followed by an INSERT rather than using the APPEND statement followed by the SORT statement
E.G. Read table INT_table with key INT_table binary search.
If SY-SUBRC <> 0.
Insert INT_table index SY-TABIX.
ENDIF - When deleting records from an internal table, if possible, WHERE should be used together with FROM...And/or to ... to enhance performance even more
E.G. Delete ITAB [from ...] [to ...] where … - When nested loops, include a 'read table itab2 with key binary serach transporting no fields + 'loop at ' itab2 from sy-tabix + key fields not equal to exit check)
- Specify the sort fields explicitly in a sort statement
- Use 'if itab[] is initial' instead of 'describe table itab lines n + if n ge 0 …..')
- Key access to multiple lines use LOOP … WHERE which is faster than LOOP/CHECK. Performance can be further enhanced if the LOOP WHERE is combined with FROM i1 and/or TO i2
- For copying internal tables of same structure use TAB_DEST[] = TAB_SRC[]
- Avoid unnecessary moves by using the explicit workarea for internal table operations
- Internal tables of same structure can be compared in logical expressions just like other data objects. If tab1[] = tab2[]. ... ENDIF
- Use DELETE itab WHERE, instead of LOOP AT itab WHERE … DELETE itab. Endloop
Database Index
- The purpose of an index is to quicken the scanning process when searching for specific records in a table.
- An index is a copy of a table reduced to particular sorted fields to enable faster access to needed data.
Creating Indexes
- Indexes may be developed when the required access to a database table is based on fields other than the primary key of the table
- Only include fields in an index if they reduce the selected data significantly
- As indexes are adjusted each time table contents are changed, create secondary indexes discerningly to minimize the impact on the system
- Place the most “common” columns at the beginning of an index. The most “common” columns are those where reports are selecting columns with no ranges - the WHERE clause for these columns is an “equal to” expression. Rearrange columns of an index to match the selection criteria. For example, if a SELECT statement is written to include columns 1 and 2 with “equal to” expressions in the where clause and column 3 and 4 are selected with value ranges, then the index should be created with columns in the sequence of 1, 2, 3, 4.
- Place columns toward the end of the index if they are either infrequently used in SELECTS or are part of reporting SELECTS that involve ranges of values
- Indexes should be small (few fields). Some optimizers are able to combine two or more indexes to execute a query. This is not possible with wide indexes
- Multiple indexes of one table should be disjoint (have few common fields), in order not to confuse the optimizer which index to use
Using Indexes
- When selecting data from a table, look at the structure of all of the available indexes and tailor the WHERE clause to take advantage of the most selective index. Use all fields in the WHERE clause in the same order for an index, as skipping one field disables the index
- Be sure to order the columns in the WHERE clause of a SELECT in the same order as an index table
Time Costs for Key Access
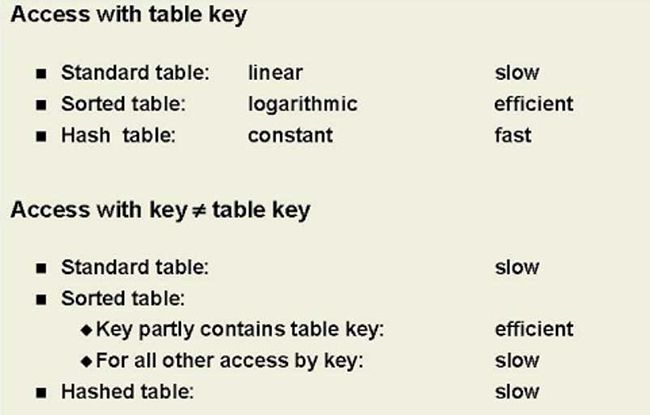
When To Use Which Table

Explicit Binary Search

Memory Costs

Points to Be Considered
- Each index slows down the inserts into the table. Updates are only slowed down if indexed fields are updated. On the other hand, the indexes increase the efficiency of reads. These tradeoffs must be weighed against one another. In general, frequently updated tables should have only few indexes while frequently selected tables might have more
- Remove unused indexes or ones that change due to report design changes
Points of Caution
- The creation of an index can affect performance adversely
- The most suitable index for the select criteria might not be the index chosen for use by the database optimizer. Validate the use of table indexes by performing a SQL trace
- Creating indexes should be done carefully and jointly with the SAP database administrator
Performance Tuning Tools
- Extended syntax check
- Runtime analysis
- SQL trace
Extended Syntax Check
- Transaction code - SLIN or go through
- Choose program - > check -> extended program check
- The system checks the entire program and allows you to run additional checks with a greater scope than the normal syntax check
Runtime Analysis
- Transaction code – SE30
- Allows you to examine the performance of any transaction, ABAP program, or function module that you create in the ABAP workbench
- Is intended for fine-tuning individual transactions, programs, and function modules
SQL Trace
- Transaction code – ST05 (performance trace tool)
- Allows you to monitor the database access from reports and transactions
- Allows you to see how the OPEN SQL statements that you use in ABAP programs are converted to standard SQL statements
- The SQL trace tells you:
- The SQL statements executed by your program.
- The values that the system uses for particular database access and changes.
- How the system converts ABAP open SQL statements (such as SELECT) into standard SQL statements.
- Where your application executes commits.
- Where your application repeats the same database access.
- The database accesses and changes that occur in the update part of your application