SAP GRC (Governance Risk Compliance)
Be it a small company or a large organization, everyone has to maintain certain rules and regulations of the business. Compliance with business regulations is essential for running day-to-day operations smoothly. Plus, it also helps companies to manage and assess risks for the business. It is important that a proper software system is in place that takes care of all these business requirements.
This is where SAP GRC comes in. It helps organizations to systematically handle their governance, risks, and compliance issues with high-end technology. In this post, we will take a closer look at the software along with its features, modules, benefits, and implementation.
What is SAP GRC?
Full form or SAP GRC stands for Governance, Risk, and Compliance. This is a powerful software that is important for companies to ensure that authorization and security standards are met. It saves a lot of time and effort when auditors approach a company. This further prevents companies from producing incorrect documents and spreadsheets.
.jpg)
This software consists of a set of tools designed to incorporate compliance within daily business operations. The compliance activities include role management, periodic risk assessment, and emergency access management. And, the compliance activities are also automated, such as compliance reporting. This, in turn, reduces the chances of frauds and malpractices in the ERP systems.
The software aids companies to integrate the compliance activities into various stages of planning, strategizing, and execution. SAP GRC also enhances operational and financial controls.
Implementation of SAP GRC
The SAP GRC software is not only limited to the IT department. It can be implemented for security, business operations, and auditing too. The software is a complete package that includes all the key functions and apps for GRC implementation. Thus, administrators and managers find it easy to monitor and regulate various compliance processes. This is because SAP GRC has a comprehensive framework.
Moreover, SAP GRC reduces the need for maintaining separate storage spaces for the installation of compliance software. Significant reduction is multiple installations for the software helps to cut a lot of business costs. This also helps in the overall improvement in business performance. It’s because all possible risks and opportunities are properly balanced using this tool.
After implementing SAP GRC, the officials are presented with a very interactive dashboard and many analytical tools. This is useful in identifying where the company might be exposed to risks. Additionally, this software implementation provides more audit information. This way officials can track the company’s progress and how well it is executing its strategies. The elements of risk management and data retention can be transformed into metrics that can be measured easily.
SAP GRC Security
The SAP GRC software is capable of handling all the control processes of the internal security model. It has tools to do this along with managing the compliance issues and probable business risks.
SAP GRC Modules
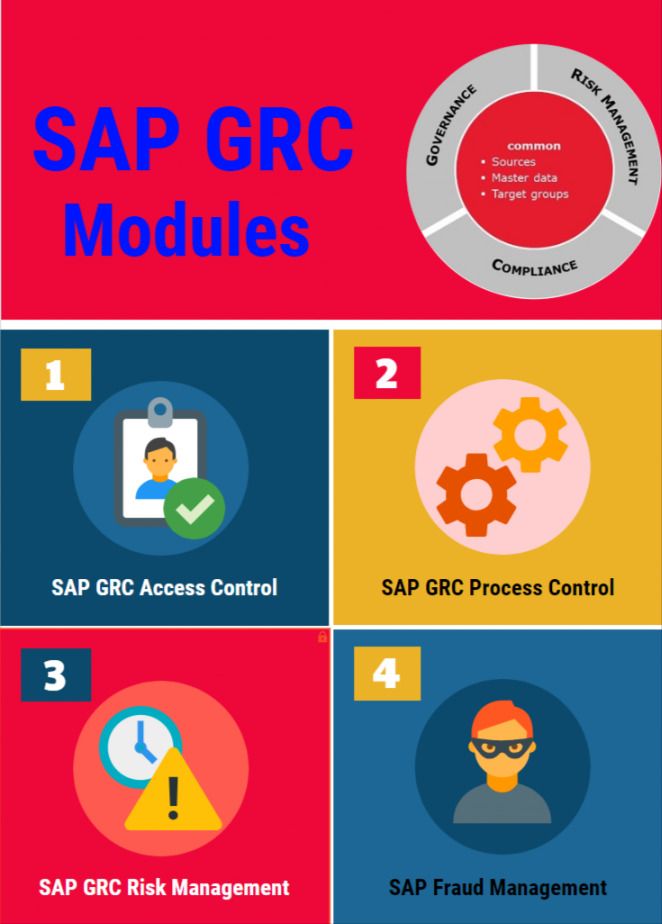
Below are some most important modules of SAP Governance Risk Compliance:
- SAP GRC Access Control
- SAP GRC Process Control
- SAP GRC Risk Management
- SAP Fraud Management
- SAP GRC Audit Management
- SAP GRC Global Trade Services
- SAP GRC Capability Model
- SAP Business Role Management
- SAP GRC Access Risk Analysis
- SAP GRC Emergency Access Management
SAP GRC Access Control
SAP GRC Access Control is software that assists companies to detect and prevent access risk violations across SAP systems. It also helps in cutting down the expenses of compliance and control. This application comes with customizable workflows and processes for changing roles. With the risk analysis engine, the app reduces the time taken for approving access to various IT systems.
It offers users self-service access submission and access requests for better access control.
SAP GRC Process Control
This software helps companies to handle their compliance processes more efficiently. It has features such as control monitoring, automated risks, testing, and analysis. Using all this, any company can improve its compliance program. Furthermore, it assists companies to align their business strategies with their goals and improve decision making.
It has an in-built workflow module that allows employees to send notifications to different stakeholders. Furthermore, there is an in-built repository that is used for managing and storing processes, legal regulations, and policies. The policies and controls can be linked to business risks and activities.
SAP GRC Risk Management
SAP GRC Risk Management is a software solution that helps in handling all types of business risks. It also enhances the risk management and mitigation activities within the company. By qualitative and quantitative analysis, the application helps company officials to determine risks.
Risks are of different types –
- Operational Risk
- Strategic Risk
- Compliance Risk
- Financial Risk
SAP GRC Risk Management offers support to handle all types of risks. The risk management process is executed in the following phases –
- Planning –The application is configured according to the business context. Aspects such as risk appetite, risk hierarchy, risk owners, and risky business activities are considered.
- Identifying Risks –This phase is where the potential risks are identified. These are associated with the risk drivers, responses, and indicators.
- Analyzing Risks –Using analytical reports and risk scenarios, the risks are analyzed in this phase. Here, the cleanup efforts are executed, modification of rules, risk modeling is done and other tools are used. This is done for understanding the risks better and developing strategies to tackle them.
- Responding to Risk –Using the appropriate controls, the risks are attended in an effective way using SAP GRC RM. The costs, benefits, and Key Risk Indicators (KRI) are all analyzed here.
- Monitoring & Reporting –In this phase, the overall risk scenario of the organization is evaluated. The identified risks are monitored and the effectiveness of risk management strategies are scrutinized. The risk events and losses associated with them are documented.
SAP Fraud Management
As the name suggests, SAP Fraud management is an effective tool used for investigating, detecting, and preventing fraud. The tool can be used in a variety of sectors such as healthcare, banking, and high-tech environment. SAP Fraud management lets users create detection strategies that can leverage the power of SAP HANA. This will be useful in screening high volumes of data.
Predictive algorithms are also used for preventing fraud.
SAP Fraud Management offers the following benefits –
- The effective alert management system allows frauds to be detected faster
- The power of SAP HANA is used for detecting frauds at the initial stages. These processes are integrated into business processes
- Using predictive analytics, frauds are prevented better and their patterns are permanently altered
- Real-time calibration and simulation can analyze large volumes of data and reduce the false positives
SAP GRC Audit Management
This software is used for enhancing the audit management processes within the organization. This improves and automates the internal audit processes. Companies use it to document business artefacts, organize work documents and develop audit reports. The tool can be integrated with other GRC solutions. This will enable companies to align their business objectives with the audit management processes.
SAP GRC audit management helps to make the auditing process smooth by offering the following benefits –
- Employees can capture audit management artefacts by using drag and drop features
- Real-time audit analytics help in obtaining better insights into the audit management process
- Using global monitoring and follow-ups, you can track, create, and manage different audit issues
- The automatic tracking tool helps in resolving audit issues faster
- It can be easily integrated with SAP Risk Management and SAP Process Control to enhance the auditing management process
SAP GRC Global Trade Services
SAP GRC GTS assists the companies to reduce the risks associated with International Trade Regulation authorities. This also helps in enhancing cross-border trade management. It automates the control tasks, global trade management processes and reduces the risks of penalties.
It offers a single repository for handling all compliance data irrespective of the size of the organization.
SAP GRC Capability Model
SAP GRC Capability Model is a model that integrates the different sub-disciplines such as audit, risk, governance, compliance, and IT into a single approach. It has 3 main capabilities –
- Analyze
- Manage
- Monitor
This also covers all the important aspects of the SAP GRC software. Using this software solution, companies can check for probable risks and take the appropriate decisions to mitigate them.
SAP GRC Access Risk Analysis
The Access Risk analysis lets users define access risks and identify access risks. It also allows users to detect access violations within the company. Checking SoD violations, authorizations, crucial transactions, profiles, and critical roles can be performed using this tool.
To analyze these violations, ARA uses a set of rules. This contains the definition of the critical authorizations. Then, the system compares these defined rules from the ruleset containing the correct authorization scopes. If any violation is detected, it will be reported.
The advantages of the ARA module are –
- Mitigating controls can be easily implemented
- Generating SoD reports aids in risks analysis
- The current processes in the company can be tackled using the SoD conflict matrix
- It offers a simulation tool for enhancing the decision-making process for granting access to new users
- Threats associated with authorization and access of users are detected swiftly
SAP GRC Emergency Access Management
SAP GRC Emergency Access Management is a set of features including SAP Access Controls. This allows users to perform the activities required to handle an emergency. Using a controlled and auditable process, the user can be assigned emergency access. The software will assign a temporary ID to the user. It will log all the activities performed by the user.
There are 2 ways to assign emergency access to a user. These are –
- By using a user ID to create a Firefighter ID
- By using a Firefighter Role
The advantages of using the EAM module are –
- It reduces the time needed for getting approval for providing privileged access to the system
- It offers a transparent policy to manage special accounts such as Firefighter ID
- Complete control over activities performed on dedicated accounts
- The software covers the most commonly used audit recommendations
- Reduces the need for manual security workflows needed to issue an emergency access credential
SAP GRC Business Role Management
This is a web-based application that lets users create business management roles. It implements the best strategies to ensure that role creation, testing and maintenance remain consistent across the implementation process.
This software allows role owners to be involved in the role-building process. They can easily perform risk analysis and document the role testing process. Furthermore, creating and maintaining role definitions is simpler with SAP GRC BRM.
BRM Module Advantages
- It offers features such as risk analysis, mitigation, role certification, and simulation
- Cost optimization in different systems and environments while role creation is possible with BRM
- The change management process for the roles can be controlled easily
- SoD risks are eliminated in roles
- The internal and external audits during the role management process are made smoother
Advantages of SAP GRC for Business
The advantages of using SAP GRC for any business are –
- This automatically removes all authorization risks in real-time. Also, new risks are prevented
- It helps in automating the provisioning process which increases the company’s productivity
- Reduces expenses of audit programs, risks management, and compliance processes
- The risks in the finance, legal and operational departments can be handled and mitigated quickly
- It helps to embed corporate and regulatory policies into the global trade processes
- Compliance programs can be tested and their results can be shared among different team members
- The software can detect and assess risks before they affect the business
- Using Cloud Identity Access Governance, SAP GRC can now support cloud applications on the platform. This further improves the risk analysis and user provisioning processes
Conclusion
All the amazing features that make SAP GRC an important part of any business are discussed here. Nowadays, companies always strive to expand their business globally. Therefore, maintaining compliance, risk, and governance issues are crucial. Thus, SAP GRC plays a vital role in managing all the issues single-handedly. As these regulatory issues are tackled by SAP GRC, company officials can focus on their business growth and expansion.
SAP GRC Other Important Resources
Tutorials
- SAP GRC Mitigation Control
What is Mitigation? The Mitigation allows you to mitigate certain risk violations that you want available to specific users or roles. This is done by creating and assigning a Mitigation Control. ... - Email notifications not sent to user in GRC Access Control 10.0
Configurations for Email notifications may not be complete or correct. Please check the following settings in the configuration.1. Go to the configuration settings SPRO-> GRC -> Access Control-& ... - Restricting Firefighter Ids from Logging in into SAP System via SAP GUI.
How to restrict Firefighter Ids from Logging in into SAP System, directly through SAP GUI.To restrict Firefighter Ids from Logging in into SAP System, directly via SAP GUI for this purpose either we n ...  Concept of Entity Level Authorization for GRC 10.0
Concept of Entity Level Authorization for GRC 10.0
What is the GRC 10.0 authorization concept and where can we use This authorization concept in the applications "Risk Management" and "Process Control" ?There are various authorizat ... Differences between Action level and Permission level
Differences between Action level and Permission level
Action Level vs Permission Level The main difference Action level and Permission level levels are following: The Action level can only compare at the transaction level. Therefore r ... Benefits of SAP GRC (Governance Risk Compliance) Software
Benefits of SAP GRC (Governance Risk Compliance) Software
Benefit from GRC (Governance, Risk and Compliance)?Undoubtedly, the top management enjoys the holistic benefit factors that are a part of the GRC software. However, the benefits spread out to other de ...- FF Email Notifications and Workflow Email Notifications are not working for certain email addresses
In GRC Access Control 10.0, some users get email notifications while others do not get any notifications for Workflow, Firefighting activity or Provisioning. Emails are working for internal email addr ... - The Flash control is not responding, Possibly the Java plug-in of the browser is deactivated or not installed
Flash Error Message When Opening Heatmap ReportUpon trying to open Heatmap report, an error message appears:The Flash control is not responding. Possibly the Java plug-in of the browser is deactivated ...  SAP GRC Access Control Module Course, Fees and Duration
SAP GRC Access Control Module Course, Fees and Duration
Goals:SAP GRC Access Control (Risk Analysis and Remediation, Superuser Privilege Management, Compliant User Provisioning and Enterprise Role Management) works in combination with SAP Business Processe ...- EUP Manager is Editable in Multi User Request
EUP is set to not Editable for Manager field, Multi User Requests Manager field show as Editable.SolutionIn Single User Request, you can add any User which is valid GRC user. It will create a Request ... - Define License Types in SAP GRC
This SAP GRC(Governance, Risk, and Compliance) tutorial, explains the step-by-step procedure to define License Types in your SAP system with the proper screenshots. What are License Types in SAP GR ... - Create Rule Set
In this SAP tutorial, you will learn step-by-step procedures to create rule sets (rule id) in SAP GRC using t-code NWBC. Path to Create Rule Set NWBC > SAP_GRC_NWBC > Rule Setup > Acc ... - Define Number Ranges for Licenses
In this SAP GRC (Governance Risk Compliance) tutorial, the SAP Users will learn the step-by-step process to define number ranges for licenses in their SAP system with proper screenshots at every ... - Difference between SCASE and GRPC_AS_REORG transactions
SCASE vs GRPC_AS_REORG What is the difference between SCASE and GRPC_AS_REORG transactions? What is recommend to use for Process Control? SOLUTION Here is the difference t-code between SCASE ... - Policy Approval in SAP GRC
In this SAP GRC (Government Risk & Compliance) tutorial, you will learn steps by step procedures to define Policy Approval in SAP GRC with proper screenshots. What is Policy Approval in SAP GRC ... - Define Legal Regulations
This SAP GRC(Governance, Risk, and Compliance) tutorial, explains the step-by-step procedure to define Legal Regulation in your SAP system with the proper screenshots. What is Legal Regul ... - Define Incoterms in SAP
In this SAP GRC tutorial, we will teach you the step-by-step process of defining new Incoterms in your SAP system with proper screenshots. What are Incoterms in SAP GRC? Incoterms in SAP GRC&nbs ...