SAP HANA
Definition or Meaning - What is SAP HANA?
Full form or SAP HANA stands for (High-Performance Analytic Appliance) is an In-Memory Database. It is the advanced ERP Solution from SAP, and can be installed cloud or on premises. It is a blend of both hardware and software due to which it incorporates various components such as
- SAP SLT or System Landscape Transformation
- SAP HANA Database
- SAP HANA Direct Extractor connection
- Replication server
- Sybase replication technology
SAP HANA Database is classified into two types such as:
- Row Store
- Column Store
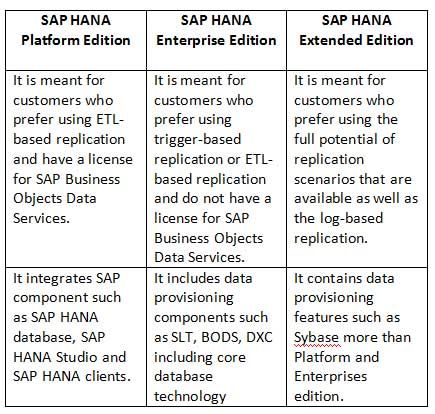
SAP HANA edition is classified into three types such as:
- SAP HANA Platform Edition
- SAP HANA Enterprise Edition
- SAP HANA Extended Edition
Why to choose SAP HANA
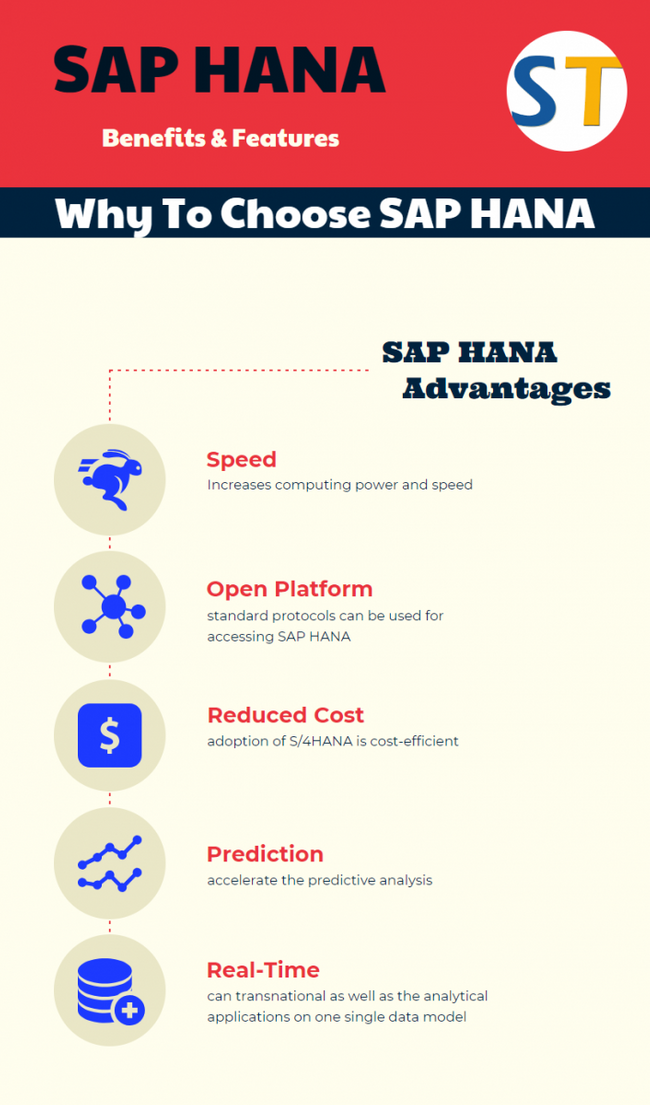
Speed: One can completely leverage the computing power of his hardware.
Real-Time: The user can run both the transactional as well as the analytical applications on one single data model, which will fully transform how the business applications are constructed and their expectations while these are being consumed.
Any Data: The user is capable of asking complex questions on any data utilizing the standard SQL for performing things which were impossible to be done earlier.
Any Sources: One can have different ways of loading the data from the existing data sources into SAP HANA and can compensate the missing functionality in remote databases with the help of these SAP HANA capabilities.
Open platform: User can use the standard protocols for accessing the SAP HANA and integrating his application with SAP HANA. Apart from this, he can also use programming language for building his application on top of SAP HANA.
Agility: SAP Fiori drives the end user interface of SAP S/4HANA. This provides for a user-friendly rendition of real-time business insights as well as intelligence on any mobile device a commendable business advantage, anytime and at any place.
Simplification: One is capable of simplifying the application development. Experience depicts that application code can be considerably reduced by as much as 75% with in-memory technologies like SAP HANA.
Consolidation: User can reduce TCO by consolidating the heterogeneous servers into the SAP HANA servers along with reducing the hardware, maintenance as well as lifecycle management.
Prediction: One can accelerate the predictive analysis and scoring with the in-database algorithms delivered out-of-the-box and can parallelly adapt the models quite frequently.
Reduced Total Cost of Ownership: The adoption of S/4HANA is quite a cost-efficient option especially while considering the fact that one can amalgamate all the analytical and transactional capabilities of various systems into a single source of truth which leads to acute and proactive business making.
SAP HANA - Advanced Capabilities for Real-time Business
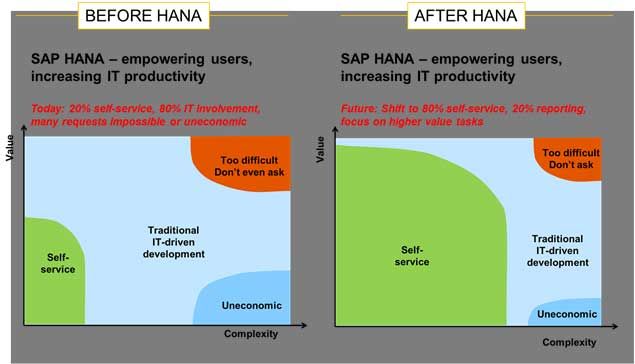
SAP HANA is an imaginary platform that combines data processing, datab, se and in-memory processing, provides libraries for planning, text processing, predictive, spatial and business analytics. It is virtually a package of software and hardware that processes real-time data and applies the benefits of in-memory computing.
It showcases advanced capabilities like data virtualization, spatial processing, predictive text analytics, etc.; simplifies the process of application development; and facilitates the tasks of processing across large structures and data sources. This module also boasts of a multiengine query processing platform that is designed to support relational, graphical and text data, in the same system.
SAP HANA accelerates client business processes and goes a long way in conceptualizing new and improvised business models, speeding data transactions and creating solutions for better business performances. With significant processing speed, smarter text mining capabilities, features to deal with huge data sizes and a lot more, SAP HANA is the most appropriate platform for the deployment of real time, next-generation applications/analytics.
Advantages of SAP HANA:
- With the help of Real-Time Data Provisioning and Real-time Reporting, decisions can be taken in no time.
- Due to the presence of In-Memory Technology, SAP HANA delivers high speeds processing on massive data and allows the user to discover and analyze all transactional and analytical data.
- SAP HANA reduces the total cost of ownership (TCO) as it requires fewer testing, hardware, and maintenance and it also reduces Total IT cost of a company.
- By leveraging innovative solutions, SAP HANA makes new business processes and business models.
- Data can be collected from several applications and data sources without disturbing the on-going business transactions.
- It helps in simplification of prevailing models, of modeling and re-modeling.
- SAP HANA can visit several data source as well as the Un-Structured and Structured data from Non-SAP or SAP data source.
- SAP HANA decreases the complication of data management and data manipulation.
- SAP HANA helps in increasing the revenue of an organization as it makes it so easy to identify the profitable sales opportunities through the entire sales related data accurately.
The four components of SAP HANA:
SAP HANA DB- Database Technology
SAP HANA Appliance
SAP HANA Application Cloud-based infrastructure
SAP HANA Studio- A compilation of tools for modelling SAP applications
Supported Operating Systems for SAP HANA
One of the following Enterprise Linux distribution products, in the below-mentioned version, is required for running SAP HANA:
- Red Hat Enterprise Linux for SAP Solutions
- Red Hat Enterprise Linux for SAP HANA
- SUSE Linux Enterprise Server for SAP Applications
- SUSE Linux Enterprise Server
SAP advise using "RHEL for SAP Solutions" or "SLES for SAP Applications" because of their features and extended support cycles. For more detailed information regarding the Linux product flavors, their feature set and benefits, please reach out to the respective Linux sales representative.
Scope and Opportunity of a Career in SAP HANA
SAP HANA is a rapidly growing field and is expected to create more lucrative career opportunities in the coming years. Reputed organizations are upgrading to the various advantages and features of this module are offering good jobs that require highly trained professionals and freshers with certification in SAP HANA. A large percentage of these professionals have a strong knowledge base of SAP BW and SAP BI or are qualified M.Techs and B.Techs.
- With an average salary of 8 lacs p.a, HANA professionals can look forward to an average growth rate in salary of about 28% each year.
- The average salary of professionals having 0-3years of experience is approximately 3.81 lacs p.a, while those with 3-7 years may expect 6.18 lacs p.a.
The top paying companies in this field are SAP Labs, Voltas, Genpact, etc. with Mumbai, Noida, Chennai and New Delhi being the most coveted locations for SAP HANA professionals.
Demand for SAP HANA Professionals:
Organizations that use SAP functional tools are plugging in SAP HANA due to which, the demand for HANA jobs are increasing each day. However, the numbers of good SAP HANA resources are much less compared to the demand, as a result of which the salary structure of a SAP HANA proficient is 15-40% more than an average IT expert. Thus, the professionals belonging to this domain get an average pay scale of about $51,994 to $145,093.
Become a Certified SAP HANA Consultant
SAP HANA is an upcoming and innovative trend. Pursuing this course with an aim of getting a certification puts candidates on a bright career path. The overview course of this module is highly beneficial for project members, business executives, IT managers, independent application consultants, BW/data warehouse consultants, IT freshers with basic awareness about SAP ERP system and many others .It can be covered in 2-5 days.
To pursue a course in SAP HANA, an individual must possess:
- Basic Knowledge about the information technology and database domains
- Insights into BI reporting tools and Business Warehouse (BW)
- A fair idea about business processes and applications
- A degree from a recognized university
SAP HANA also serves to be feasible domain for professional and budding data modelers who essentially handle huge databases that support real time applications.
SAP HANA in-memory Business Consultant: He/she should understand how in-memory technology technologies can cause interruption in the businesses and knows how to apply the technology concepts to business scenarios.
SAP HANA Performance Consultant: He/she is responsible to take the models developed by the Business Consultants and then creates architectures, solutions and designs using SAP HANA Modeller tool.
SAP HANA Operations Consultant: He/she should understand technical architecture, Linux, in what way SAP HANA should be installed or migrate systems, along with a basic understanding of SAP Basis.
SAP HANA BW Consultant: The individual should have specific skills about architecting, re-architecting and modeling BW solutions in SAP HANA.
SAP HANA Application Developer: He/she should understand the existing development platform, and in-memory computing concepts to build ABAP applications using the HANA database, or mobile applications using the HANA XS Application Services layer.
SAP HANA Security Consultant: This is a niche area which includes security design, access control and security models. The individual should have skills in SAP ABAP, Java, Sap HANA, enterprise portal etc.
SAP HANA Project Manager: He/she should have prior experience with SAP HANA implementation or enhancement projects along with at least 6 years of project management practical experience.
Tutorials
- SAP HANA set to change the face of Indian Railways Ticketing System
Did you know that at an average Indian Railways sells close to 21 million tickets daily? Almost 250 million tickets are booked via IRCTC annually. At 8:00am when the booking window opens thousands of ...  SAP HANA Certification Cost Fee and Course Duration in India
SAP HANA Certification Cost Fee and Course Duration in India
SAP HANA course is modelled to enable its audience with the skills that will help them to deliver a substantial new revenue opportunity and at the same time make them to adapt changes in the competiti ... Job Profile & Salary Package for SAP HANA Consultant
Job Profile & Salary Package for SAP HANA Consultant
SAP HANA is advancement and thus is offering good jobs in highly reputed organizations that are moving towards SAP HANA. Though the job requires highly trained professionals and thus seeks employees w ...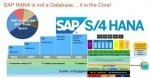 Difference between S/4HANA and SAP Suite on HANA
Difference between S/4HANA and SAP Suite on HANA
SAP S/4HANA Vs. SAP Suite on HANABetween SAP Suite on HANA and SAP S/4HANA, some level of confusion still exist which I got know after speaking with a large number of people. For those who are wrestli ... Install SAP HANA Studio & HANA Client on a Windows System
Install SAP HANA Studio & HANA Client on a Windows System
At the end of this tutorial, you will know: How to download SAP HANA Client How to download SAP HANA Studio How to download SAPCAR Extract the SAR Files to desktop Install SAP HANA CLIEN ... Start and Stop the Script Server in SAP HANA Database
Start and Stop the Script Server in SAP HANA Database
How to Start and Stop the Script Server in SAP HANA Database?The SAP In-Memory Database displayed the error message:34091 "No ScriptServer available."To improve the performance of certain da ... Difference between Oracle and SAP HANA in SQL Queries
Difference between Oracle and SAP HANA in SQL Queries
SAP HANA SQL vs Oracle SQLSQL statements created in Oracle wont work with SAP HANA it will return unexpected results, here are some transaction difference between Oracle and SAP HANA in SQL Queries. ...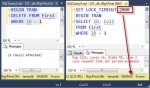 SAP HANA Database Suffers from Lock Waits
SAP HANA Database Suffers from Lock Waits
How to check if SAP HANA database suffers from lock waits?On a very elementary level you can identify lock waits based on the thread states.Current threads can be displayed via: Transaction DBACOCKPIT ...- Qualifications and Skills Requires to become a SAP HANA Consultant
SAP HANA is a new trend and is sure to be adapted by many SAP users because of its benefits. Thus pursuing this course and getting certification is sure to open gateways towards a bright career p ...  SAP HANA Studio: A Complete Guide
SAP HANA Studio: A Complete Guide
SAP HANA Studio is a tool based on Eclipse which is used for developing artifacts in a HANA server. For HANA system, SAP HANA studio is the chief development environment as well as the key administrat ...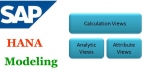 SAP HANA Modeling a Complete Step-by-Step Guide
SAP HANA Modeling a Complete Step-by-Step Guide
This tutorial is designed to help users successfully use the HANA studio to create various SAP models, packages and Views. By the end of this tutorial you will learn: What does the Quick Laun ...- HANA Disable Password Lifetime using SQL Statement for Technical Users
Your application uses a technical user to perform database queries as required by the application.For the user, you encounter the following error/warning messages "user's password WILL EXPIRE ...  CO-PA Issues in S/4 HANA Finance (SFIN)
CO-PA Issues in S/4 HANA Finance (SFIN)
FAQ for CO-PA issues in S/4 HANA Finance (SFIN)1. What could be the reason for getting error message FCO_COPA006 after upgrading to SFIN?In SAP Accounting, for using the new CO-PA features for SAP Bus ...- Log Volume is full (log mode = legacy) and the database doesn't accept any new requests.
The logvolume is full and the database doesn't accept any new requests.If the log_mode is set to legacy the logvolume keeps all log segments since the last full backup in the logvolume. If no back ... 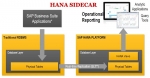 SAP HANA Sidecar Scenario
SAP HANA Sidecar Scenario
SAP HANA SideCarSAP HANA Sidecar helps a person to keep continue with his already existing system same along with the use of SAP HANA in form of secondary database as he was doing before. The already ... SAP HANA Architecture Overview
SAP HANA Architecture Overview
Compared to other databases, the architecture of SAP HANA is exclusive and very distinct. The SAP HANA database is built on C++ and operates on SUSE Linux Enterprises Server. The aim of the SAP HANA d ... Differences between SAP HANA and Oracle
Differences between SAP HANA and Oracle
SAP HANA vs. OracleListed below are some of the basic differences between Oracle and SAP HANA: Name Oracle SAP HANA Developer Oracle SAP ... HANA Homogeneous System Copy Backup/Recovery Method
HANA Homogeneous System Copy Backup/Recovery Method
How to use backup to copy for an existing SAP system on SAP HANA?We want to copy the BW system PRD connected to the database PR1 to the BW system DEV connected to the database DV1. The name of the ABA ...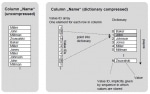 Compression Types Exist in SAP HANA
Compression Types Exist in SAP HANA
Which compression types exist? The following compression types exist: Compression type M_CS_COLUMNS -> COMPRESSION_TYPE Valid for Details Typical Scenario ...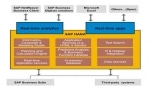 SAP HANA Database: Issue Solved with the Revision 60
SAP HANA Database: Issue Solved with the Revision 60
Issue Solved with the Revision 60 of SAP HANA DatabaseStored procedure with cursor on a table on a different host might fail.The indexserver trace file contains the following message:"GenericFail ...