Compared to other databases, the architecture of SAP HANA is exclusive and very distinct. The SAP HANA database is built on C++ and operates on SUSE Linux Enterprises Server. The aim of the SAP HANA database is to offer a main-memory centric data management platform to support SQL. To multiple machines, SAP HANA Database is distributed.
Know about SAP HANA architecture:
SAP HANA database comprises of multiple servers namely
- Index server
- Name Server
- Statistic Server
- Preprocessor Server
- XS Engine
Among all these index server is the most significant component of the entire server.
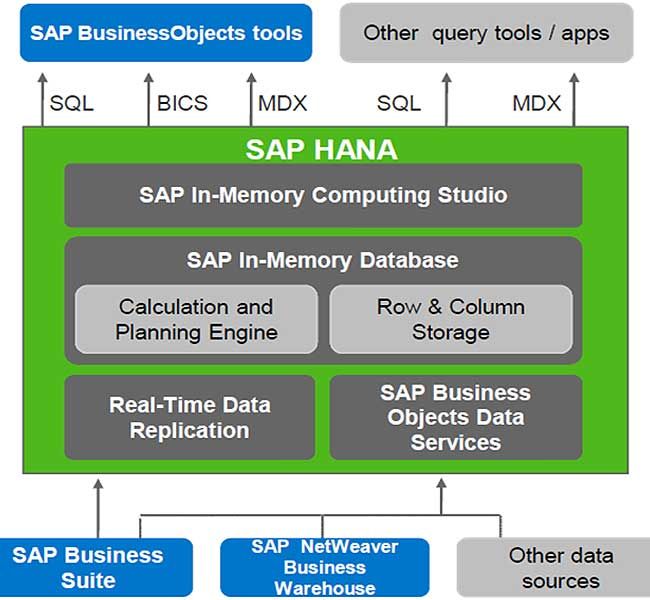
Index Server: It is the key SAP HANA database component and comprises actual data stores and the engine for data processing. In situation of authentic sessions and connections while SQL or MDX get started against the SAP HANA system, an index server maintains these commands and takes a series of actions in order to achieve a particular end.
Name Server: It comprises of thorough information regarding the system landscape. The name server comprises of information about each running component and location of data on the server in distributed server. In addition, the name server comprises of information about the server on which data exists.
Statistic Server: This server assists in collecting the data for the system monitor and aids in understanding the SAP HANA system’s health. The duty of this server is to collect the data related to source distribution/consumption, status, and performance of the SAP HANA system. This server monitors the status of numerous alert monitors and the information gathered by statistics server.
This server also offers a history of measurement data for additional analysis.
Preprocessor Server: For analyzing text and extracting data from a text when the search function is used, Preprocessor Server is used. The abilities of preprocessor server are exploited by index server during the analysis of the text data and probing.
XS Engine: This is found in the XS Server. This permits external application and developers to utilize SAP HANA database through the XS Engine client. To transmit data through XS engine for HTTP server, the external client application may use HTTP.
- By utilizing the XS Engine, application developers construct applications. By utilizing a web browser, the users access the app through HTTP.
- In the SAP HANA database, the persistent model is transformed into a consumption model for clients to access it through HTTP.
- This permits the association to host system services which are a portion of the SAP HANA database.
Different Components present in SAP HANA
- SAP Host Agent:The SAP Host Agent must be set up on all systems that are connected to the SAP landscape as per the new approach from SAP. To be able to handle the system and Software Update Manager (SUM) for programmed informs, it is used by Adaptive Computing Controller (ACC).
- LM-structure: The information about current installation details is included in LM-structure for SAP HANA. In the course of automatic updates, this data will be used by the SUM.
- SAP Solution Manager diagnostic agent: To monitor the SAP HANA system, SAP Solution Manager diagnostic agent offers all data to SAP Solution Manager (SAP SOLMAN). This agent offers information about the database state and common data about the system, such as alerts, memory or CPU and disk usage once the SAP SOLMAN is combined with the SAP HANA system.
Read more about Steps to Add New HANA System in SAP HANA Studio
- SAP HANA Studio repository: To update the SAP HANA studio to advanced versions, the SAP HANA Studio repository is used by the end users.
- Software Update Manager for SAP HANA: From the SAP Marketplace, the Software Update Manager for SAP HANA provides updates of SAP HANA automatically. It also offers updates on fixing the SAP host agent.
- Studio repository is distributed to the end users by the help of this component.
Explanation on IMCE (SAP in-memory computing engine) and its components:
The IMCE or the SAP in-memory computing engine is the main engine for the next generation SAP great-performance, in-memory solutions. Technologies such as in-memory computing, massively parallel processing (MPP), columnar databases, and data compression are influenced by the SAP in-memory computing (IMCE) engine to permit establishments to discover and evaluate quickly huge bulks of transactional and critical data from all over the organization in real time. The SAP in-memory computing database provides the below given capabilities:
- With built-in support for row and columnar data stores, the IMCE provides complete ACID that is atomicity, consistency, isolation, and durability transactional capabilities.
- For accessing non-SAP data and SAP data sources, the integrated lifecycle management competences and data integration competences.
- For data and life cycle management, data modeling, and data security SAP in-memory computing engine includes tools.
- To provide immediate results from analysis and transactions, the SAP IMCE in the main memory permits the processing of huge quantities of real-time data.
- The SAP IMCE supports and includes a high-performance calculation engine that implants procedural language support straight into the core of the database.
SAP in-memory computing engine in SAP HANA
- It is a column-oriented, in-memory database technology.
- At the core of SAP HANA, the IMCE is a powerful calculation engine.
- Matched to systems that read data from disks, highly accelerated performance can be achieved as data resides in the Random Access Memory (RAM).
- It allows creating and performing data calculations.
- Tools for data modeling activities, data and life cycle management, data security are included in SAP IMCE Studio.
For SAP HANA table two storage types exist namely:
Row type storage (For Row Table): It stores the relational data in rows, like the storage mechanism of traditional database systems.
Column type storage (For Column Table): It stores the massive quantities of relational data in column-optimized tables that are combined and used in investigative operations. Compared to the column-based store, the row based store is more enhanced for write operations and has a lesser compression rate and query performance rate.
- At the time of creating a table, the engine that is used for storing data can be nominated on the basis of per-table.
- During normal operation of the SAP HANA database, the Tables are full at start up in the row-based store while in the event of column-based stores; tables can be either full at start up or on request.
- Both engines deliver data persistency that is steady in case of both engines.
- All transactions dedicated in the SAP HANA database are kept/saved/referenced by the logger.
- Log volumes use the flash technology storage to get great I/O performance and little latency.
- Through a variety of interfaces, the relational engines can be retrieved.
- SQL (JDBC/ODBC), MDX (ODBO), and BICS (SQLDBC) are supported by SAP HANA database.
- Till calculations are done, the calculation engine does all the estimations in the database and the no data transfers into the application layer.
Read more about Key Perspectives of SAP HANA Studio
Session management
- For the database clients, this component makes and handles sessions and connections.
- A set of parameters are retained in the backend by the system once a session is created. Auto-commit settings and the current transaction isolation level are the parameters that are included.
- Using SQL statements database clients’ converse with the SAP HANA database after a session is established.
- All statements are treated as transactions in SAP HANA database.
Transaction manager
It is the component that organizes database transactions, maintains the monitoring of the transaction isolation, and retains track of active and closed transactions. It informs the elaborate storage engines about the running or closed transactions. This allows them to perform necessary actions once a transaction is devoted or rolled back. To achieve atomic and durable transactions, it collaborates with the persistence layer.
- The atomic transaction is a series of database operations where either everything occurs or nothing occurs.
- The durable transactions guarantees the transactions that have been devoted will survive permanently.
- The customer needs are examined and implemented by a set of components précised as execution control and request processing.
- The customer needs are examined by a request parser and is then send off to the responsible component.
- To the transaction manager, the transaction control statements are forwarded while the metadata manager receives the data definition statements.
- For domain-specific models, the SAP HANA database has fitted support and it provides scripting competences that permit calculations that are application-specific to operate within the database.
- To enable development and parallelization, SQLScript is designed.
- By using SQL queries for set handling, the SQLScript is created on side- effect free functions that work on tables.
- The planning engine component permits financial preparation applications to perform simple planning processes in the database layer.
- An innovative version of a dataset will be made as a copy of a current one, when applying filters/transformations.
Metadata manager
- It aids to access metadata.
- It comprises of a range of objects such as definitions of tables, SQLScript function definitions, views and indexes, and object store metadata. In one common catalog all these sorts of metadata are kept.
- In the row store, metadata is stored in tables.
- For metadata management, SAP HANA features such as multi-version concurrency control (MVCC) and transaction support are used.
- In the case of a circulated database methods, central metadata is shared across the servers.
Persistence layer
- It is responsible for durability and atomicity of transactions.
- Post a restart this layer ensures that the database is returned to the most current dedicated state and ensures that the transactions are either entirely executed or totally rolled back.
- A blend of write-ahead logs, shadow paging, and savepoints are used by the Persistence layer to achieve this in an effective way.
- For writing and reading, the persistence layer also offers interfaces. It also comprises of SAP HANA’s logger that handles the transaction log.
Read more here about Persistence Layer in SAP HANA Database
Authorization manager
- To check the necessary privileges for users in order to implement the demanded operations, the authorization manager is entreated by other database components of SAP HANA.
- Performing a specified operation (for example select, create, update and execute data manipulation languages) on a specified object such as a table, view, and SQLScript function is granted by a privilege.
- For analytic queries, analytic privileges signify filters or hierarchy, and they move the limitations from one place to the other.
- In SAP HANA, analytic privileges such as allowing access to values with a definite blend of dimension qualities are supported.
- The SAP HANA database (sign in with username and password), or authentication that is given to exterior authentication providers third-party such as an LDAP directory helps in authenticating the user.
Read more about Steps to Download and Install SAP HANA Studio