ABAP Book
 ABAP Programming & Coding Standards
ABAP Programming & Coding Standards
This document is a compilation of possible ABAP programming and efficiency standards and will provide guidance in creating readable, maintainable code ...- SAP BC 400
SAP BC 400 BC400 ABAP Workbench Concepts and Tools.................................................. 1 Copyright................................. ... 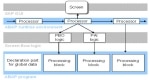 Object Oriented Programming in ABAP
Object Oriented Programming in ABAP
Structure of an ABAP ProgramProcedural Programming Information systems used to be defined primarily by their functions: data and functions were ... Different Steps for ALV Function Module
Different Steps for ALV Function Module
SAP provides a set of ALV (ABAP LIST VIEWER) function modules, which can be put into use to embellish the output of a report. This set of ALV function ...- ABAP Code Sample to Upload Data Using BDC Recording
How to Upload Data to ABAP Code Sample to using BDC Recording? Code samples are intended for educational use only, not deployment. They are unteste ... - Skipping of document numbers in SAP Number Range Object
Skipping of document numbers in SAP Number Range Object SAP Number Range Object For more tips, tutorials, Interview questions, certification ... - Internal Tables Processing
Identifying Table LinesInternal Table Index:The sequential number of a table line. Created and managed automatically by the system. Can be used with t ...  SAP File Explorer- Overview
SAP File Explorer- Overview
With SAP File Explorer I tried to mimic the Windows Explorer in the SAP environment.It’s main purpose is to access the server system files using ...- SAP SYSTEM MEASUREMENT GUIDE
1 SAP License Audit . . . . . . . . . . . . . . . . . . .71.1 Use . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2 Named Users . . . . . ... - Step-by-Step Guide for using LSMW to Update Customer Master Records
Step-by-Step Guide for using LSMW to Update Customer Master Recordsby Mitresh Kundalia, Senior FI/CO Consultant LSMW to Update Customer Master Re ...  Trigger workflow when a New Vendor is Created in SAP.
Trigger workflow when a New Vendor is Created in SAP.
Trigger workflow when a New Vendor is Created in SAP: Step by Step Process This document shows step by step process for the creation of work-flow, ... Defining Selection Screen in ABAP
Defining Selection Screen in ABAP
Selection Screen Creation and use ABAPObjective Concepts associated with The creation and use of selection screens in ABAP reports The SELECT-OPTIONS ...- Naming Conventions and Programming Standard Operating Procedure
NCH Development Guidance Naming Conventions and Programming Standards1. INTRODUCTIONDevelopment programming standards and consistent naming convention ... - Invoice Splitting for Retention Money
Document Purpose: To split Retention Money component at the time of Invoice Verification SAP ABAP_Functional Document PROJECT SHIELD Functional S ...
1
×